Introducción a S.Q.L.
El Lenguaje de consulta estructurado (En inglés] Structured Query Language) es un lenguaje declarativo de acceso a bases de datos relacionales que permite especificar diversos tipos de operaciones sobre las mismas. Una de sus características es el manejo del álgebra y el cálculo relacional permitiendo lanzar consultas con el fin de recuperar -de una forma sencilla- información de interés de una base de datos, así como también hacer cambios sobre la misma.
El SQL es un lenguaje de acceso a bases de datos que explota la flexibilidad y potencia de los sistemas relacionales permitiendo gran variedad de operaciones sobre los mismos.
SqlPlus
Para poder escribir sentencias SQL al servidor Oracle, éste incorpora la herramienta SQL*Plus. Toda instrucción SQL que el usuario escribe, es verificada por este programa. Si la instrucción es válida es enviada a Oracle, el cual enviará de regreso la respuesta a la instrucción; respuesta que puede ser transformada por el programa SQL*Plus paramodificar su salida.
Para que el programa SQL*Plus funcione en el cliente, el ordenador cliente debe haber sido configurado para poder acceder al servidor Oracle. En cualquier caso al acceder a Oracle con este programa siempre preguntará por el nombre de usuario y contraseña.
Estos son datos que tienen que nos tiene que proporcionar el administrador (DBA) de la base de datos Oracle.
Para conectar mediante SQL*Plus podemos ir a la línea de comandos y escribir el texto sqlplus. A continuación aparecerá la pantalla:
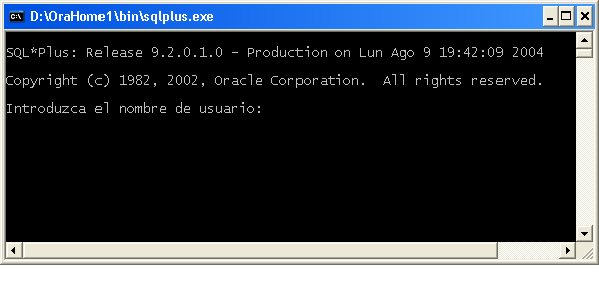
En esa pantalla se nos pregunta el nombre de usuario y contraseña para acceder a la base de datos (información que deberá indicarnos el administrador o DBA). Tras indicar esa información conectaremos con Oracle mediante SQL*Plus, y veremos aparecer el símbolo:
SQL>
Tras el cual podremos comenzar a escribir nuestros comandos SQL. Ese símbolo puede cambiar por un símbolo con números 1, 2, 3, etc.; en ese caso se nos indica que la instrucción no ha terminado y la línea en la que estamos.
Otra posibilidad de conexión consiste en llamar al programa SQL*Plus indicando contraseña y base de datos a conectar.
El formato es:
slplus usuario/contraseña@nombreServicioBaseDeDatos
Ejemplo:
slplus usr1/miContra@inicial.forempa.net
En este caso conectamos con SQL*Plus indicando que somos el usuario usr1 con contraseña miContra y que conectamos a la base de datos inicial de la red forempa.net. El nombre de la base de datos no tiene porque tener ese formato, habrá que conocer como es el nombre que representa a la base de datos como servicio de red en la red en la que estamos.
Versión gráfica de SQL*Plus
Oracle incorpora un programa gráfico para Windows para utilizar SQL*Plus. Se puede llamar a dicho programa desde las herramientas instaladas en el menú de programas de Windows, o desde la línea de programas escribiendo sqlplusw. Al llamarle aparece esta pantalla:
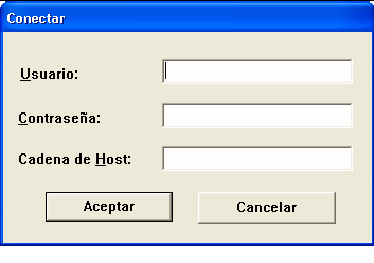
Como en el caso anterior, se nos solicita el nombre de usuario y contraseña. La cadena de Host es el nombre completo de red que recibe la instancia de la base de datos a la que queremos acceder en la red en la que nos encontramos.
También podremos llamar a este entorno desde la línea de comandos utilizando la sintaxis comentada anteriormente. En este caso:
slplusw usuario/contraseña@nombreServicioBaseDeDatos
Esta forma de llamar al programa permite entrar directamente sin que se nos pregunte por el nombre de usuario y contraseña.
iSQL*Plus
Es un producto ideado desde la versión 9i de Oracle. Permite acceder a las bases de datos Oracle desde un navegador. Para ello necesitamos tener configurado un servidor web Oracle que permita la conexión con la base de datos. Utilizar iSQL*Plus es indicar una dirección web en un navegador, esa dirección es la de la página iSQL*Plus de acceso a la base de datos.
Desde la página de acceso se nos pedirá nombre de usuario, contraseña y nombre de la base de datos con la que conectamos (el nombre de la base de datos es el nombre con el que se la conoce en la red). Si la conexión es válida aparece esta pantalla:
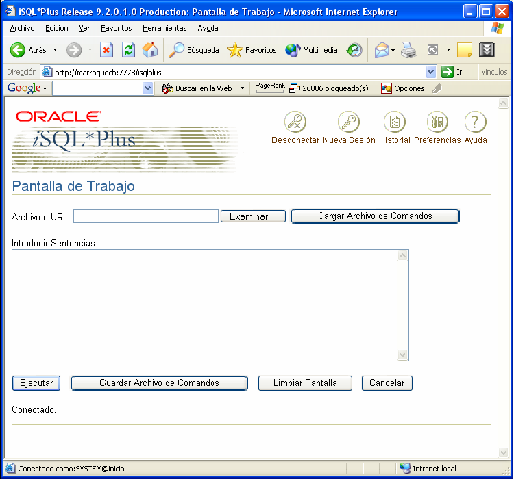
Otras Aplicaciones de desarrollo SQL
Golden: Golden es una herramienta de consulta con muchas funciones adicionales, ofrece compatibilidad con SQLPlus.
TOAD: Ees una aplicación de software de desarrollo SQL y administración de base de datos, considerada una herramienta útil para los administradores de base de datos (DBAs) y desarrolladores. Está disponible para las siguientes bases de datos: Oracle, Microsoft SQL Server, IBM DB2, y MySQL.
Lenguaje de definición de datos (DDL)
El lenguaje de definición de datos (en inglés Data Definition Language, o DDL), es el que se encarga de la modificación de la estructura de los objetos de la base de datos. Existen cuatro operaciones básicas: CREATE, ALTER, DROP y TRUNCATE.
Tipos de Datos en Oracle
| TIPO |
CARACTERÍSTICAS |
OBSERVACIONES |
| CHAR |
Cadena de caracteres (alfanuméricos) de longitud fija |
Entre 1 y 2000 bytes como máximo. Aunque se introduzca un valor más corto que el indicado en el tamaño, se rellenará al tamaño indicado. Es de longitud fija, siempre ocupará lo mismo, independientemente del valor que contenga |
| VARCHAR2 |
Cadena de caracteres de longitud variable |
Entre 1 y 4000 bytes como máximo. El tamaño del campo dependerá del valor que contenga, es de longitud variable. |
| VARCHAR |
Cadena de caracteres de longitud variable |
En desuso, se utiliza VARCHAR2 en su lugar |
| NCHAR |
Cadena de caracteres de longitud fija que sólo almacena caracteres Unicode |
Entre 1 y 2000 bytes como máximo. El juego de caracteres del tipo de datos (datatype) NCHAR sólo puede ser AL16UTF16 ó UTF8. El juego de caracteres se especifica cuando se crea la base de datos Oracle |
| NVARCHAR2 |
Cadena de caracteres de longitud variable que sólo almacena caracteres Unicode |
Entre 1 y 4000 bytes como máximo. El juego de caracteres del tipo de datos (datatype) NCHAR sólo puede ser AL16UTF16 ó UTF8. El juego de caracteres se especifica cuando se crea la base de datos Oracle |
| LONG |
Cadena de caracteres de longitud variable |
Como máximo admite hasta 2 GB (2000 MB). Los datos LONG deberán ser convertidos apropiadamente al moverse entre diversos sistemas. Este tipo de datos está obsoleto (en desuso), en su lugar se utilizan los datos de tipo LOB (CLOB, NCLOB). Oracle recomienda que se convierta el tipo de datos LONG a alguno LOB si aún se está utilizando. No se puede utilizar en claúsulas WHERE, GROUP BY, ORDER BY, CONNECT BY ni DISTINCT Una tabla sólo puede contener una columna de tipo LONG. Sólo soporta acceso secuencial. |
| LONG RAW |
Almacenan cadenas binarias de ancho variable |
Hasta 2 GB. En desuso, se sustituye por los tipos LOB. |
| RAW |
Almacenan cadenas binarias de ancho variable |
Hasta 32767 bytes. En desuso, se sustituye por los tipos LOB. |
| LOB (BLOG, CLOB, NCLOB, BFILE) |
Permiten almacenar y manipular bloques grandes de datos no estructurados (tales como texto, imágenes, videos, sonidos, etc) en formato binario o del carácter |
Admiten hasta 8 terabytes (8000 GB). Una tabla puede contener varias columnas de tipo LOB. Soportan acceso aleatorio. Las tablas con columnas de tipo LOB no pueden ser replicadas. |
| BLOB |
Permite almacenar datos binarios no estructurados |
Admiten hasta 8 terabytes |
| CLOB |
Almacena datos de tipo carácter |
Admiten hasta 8 terabytes |
| NCLOB |
Almacena datos de tipo carácter |
Admiten hasta 8 terabytes. Guarda los datos según el juego de caracteres Unicode nacional. |
| BFILE |
Almacena datos binarios no estructurados en archivos del sistema operativo, fuera de la base de datos. Una columna BFILE almacena un localizador del archivo a uno externo que contiene los datos |
Admiten hasta 8 terabytes. El administrador de la base de datos debe asegurarse de que exista el archivo en disco y de que los procesos de Oracle tengan permisos de lectura para el archivo .
|
| ROWID |
Almacenar la dirección única de cada fila de la tabla de la base de datos |
ROWID físico almacena la dirección de fila en las tablas, las tablas en clúster, los índices, excepto en las índices-organizados (IOT). ROWID lógico almacena la dirección de fila en tablas de índice-organizado (IOT). Un ejemplo del valor de un campo ROWID podría ser: “AAAIugAAJAAC4AhAAI”. El formato es el siguiente: Para “OOOOOOFFFBBBBBBRRR”, donde: OOOOOO: segmento de la base de datos (AAAIug en el ejemplo). Todos los objetos que estén en el mismo esquema y en el mismo segmento tendrán el mismo valor. FFF: el número de fichero del tablespace relativo que contiene la fila (fichero AAJ en el ejemplo). BBBBBB: el bloque de datos que contiene a la fila (bloque AAC4Ah en el ejemplo). El número de bloque es relativo a su fichero de datos, no al tablespace. Por lo tanto, dos filas con números de bloque iguales podrían residir en diferentes datafiles del mismo tablespace. RRR: el número de fila en el bloque (fila AAI en el ejemplo). Este tipo de campo no aparece en los SELECT ni se puede modificar en los UPDATE, ni en los INSERT. Tampoco se puede utilizar en los CREATE. Es un tipo de datos utilizado exclusivamente por Oracle. Sólo se puede ver su valor utilizando la palabra reservada ROWID, por ejemplo: select rowid, nombre, apellidos from clientes Ejemplo 2: SELECT ROWID, SUBSTR(ROWID,15,4) “Fichero”, SUBSTR(ROWID,1,8) “Bloque”, Ejemplo 3: una forma de saber en cuántos ficheros de datos está alojada una tabla: SELECT COUNT(DISTINCT(SUBSTR(ROWID,7,3))) “Numero ficheros ” FROM facturacion |
| UROWID |
ROWID universal |
Admite ROWID a tablas que no sean de Oracle, tablas externas. Admite tanto ROWID lógicos como físicos. |
| NUMBER |
Almacena números fijos y en punto flotante |
Se admiten hasta 38 dígitos de precisión y son portables a cualquier entre los diversos sistemas en que funcione Oracle. Para declarar un tipo de datos NUMBER en un CREATE ó UPDATE es suficiente con: nombre_columna NUMBER opcionalmente se le puede indicar la precisión (número total de dígitos) y la escala (número de dígitos a la derecha de la coma, decimales, los cogerá de la precisión indicada): nombre_columna NUMBER (precision, escala) Si no se indica la precisión se tomará en función del número a guardar, si no se indica la escala se tomará escala cero. Para no indicar la precisión y sí la escala podemos utilizar: nombre_columna NUMBER (*, escala) Para introducir números que no estén el el formato estándar de Oracle se puede utilizar la función TO_NUMBER. |
| FLOAT |
Almacena tipos de datos numéricos en punto flotante |
Es un tipo NUMBER que sólo almacena números en punto flotante |
| DATE |
Almacena un punto en el tiempo (fecha y hora) |
El tipo de datos DATE almacena el año (incluyendo el siglo), el mes, el día, las horas, los minutos y los segundos (después de medianoche). Oracle utiliza su propio formato interno para almacenar fechas. Los tipos de datos DATE se almacenan en campos de longitud fija de siete octetos cada uno, correspondiendo al siglo, año, mes, día, hora, minuto, y al segundo. Para entrada/salida de fechas, Oracle utiliza por defecto el formato DD-MMM-AA. Para cambiar este formato de fecha por defecto se utiliza el parámetro NLS_DATE_FORMAT. Para insertar fechas que no estén en el mismo formato de fecha estándar de Oracle, se puede utilizar la función TO_DATE con una máscara del formato: TO_DATE (el “13 de noviembre de 1992″, “DD del MES, YYYY”) |
| TIMESTAMP |
Almacena datos de tipo hora, fraccionando los segundos |
|
| TIMESTAMP WITH TIME ZONE |
Almacena datos de tipo hora incluyendo la zona horaria (explícita), fraccionando los segundos |
|
| TIMESTAMP WITH LOCAL TIME ZONE |
Almacena datos de tipo hora incluyendo la zona horaria local (relativa), franccionando los segundos |
Cuando se usa un SELECT para mostrar los datos de este tipo, el valor de la hora será ajustado a la zona horaria de la sesión actual |
| XMLType |
Tipo de datos abstracto. En realidad se trata de un CLOB. |
Se asocia a un esquema XML para la definición de su estructura. |
| BOOLEAN |
Almacena valores lógicos boléanos , verdadero o falso |
Válido en PLSQL, este tipo de datos no existe en Oracle 8i/9i. |
De los tipos anteriores, los comunmente utilizados son: VARCHAR2 (cadenas de texto no muy grandes), DATE (fechas, horas), NUMBER (números), BLOB (ficheros de tipo word, excel, access, video, sonido, imágenes, etc) y CLOB (cadenas de texto muy grandes).
Create
Create Table
La estructura de la sentencia de creación de tablas es:
CREATE [GLOBAL TEMPORARY] TABLE [esquema.]tabla
columna datatype [DEFAULT expr] [column_constraint(s)]
[,columna datatype [,...]]
table_constraint
table_ref_constraint
[ON COMMIT {DELETE|PRESERVE} ROWS]
storage_options [COMPRESS int|NOCOMPRESS]
[LOB_storage_clause][varray_clause][nested_storage_clause] [XML_type_clause]
Partitioning_clause
[[NO]CACHE] [[NO]ROWDEPENDENCIES] [[NO]MONITORING] [PARALLEL parallel_clause]
[ENABLE enable_clause | DISABLE disable_clause]
{ENABLE|DISABLE} ROW MOVEMENT
[AS subquery]
Queda mas claro con unos ejemplos:
create table T_PRODUCTOS
(
numproduct number,
desproduct varchar2(10)
);
Es posible definir restricciones (constraint) con la sentencia CREATE.
create table T_CLIENTES
(
numclie number primary key,
desclie varchar2(10)
) ;
create table T_PEDIDOS
(
numpedido number primary key,
fecpedido date,
numclient references T_CLIENTES
);
Una clave primaria (primary key) necesita tener asociado un indice unico (unique index). Es posible especificar el tablespace donde queremos crear el indice.
create table T_PEDIDOS(
numpedido number primary key using index tablespace users ,
fecpedido date,
numclient references T_CLIENTES
)
Organization external , el siguiente script crea una table externa:
create table (….)
organization external (
type oracle_loader
default directory some_dir
access parameters (
records delimited by newline
fields terminated by ‘,’
missing field are values null
)
location (‘fichero.csv’)
)
reject limit unlimited;
Nested tables
create or replace type item as object (
item_id Number ( 6 ),
descr varchar2(30 ),
quant Number ( 4,2)
);
/
create or replace type items as table of item;
/
create table bag_with_items (
bag_id number(7) primary key,
bag_name varchar2(30) not null,
the_items_in_the_bag items
)
nested table the_items_in_the_bag store as bag_items_nt;
Create Index
Los indices se usan para mejorar el rendimiento de las operaciones sobre una tabla.
En general mejoran el rendimiento las SELECT y empeoran (minimamente) el rendimiento de los INSERT y los DELETE.
Una vez creados no es necesario nada más, oracle los usa cuando es posible (ver EXPLAIN PLAN).
En oracle existen tres tipos de indices:
-
Table Index:
CREATE [UNIQUE|BITMAP] INDEX [esquema.]index_name
ON [esquema.]table_name [tbl_alias]
(col [ASC | DESC]) index_clause index_attribs
-
Bitmap Join Index:
CREATE [UNIQUE|BITMAP] INDEX [esquema.]index_name
ON [esquema.]table_name [tbl_alias]
(col_expression [ASC | DESC])
FROM [esquema.]table_name [tbl_alias]
WHERE condition [index_clause] index_attribs
-
Cluster Index:
CREATE [UNIQUE|BITMAP] INDEX [esquema.]index_name
ON CLUSTER [esquema.]cluster_name index_attribs
Las clausulas posibles para los índices son:
LOCAL STORE IN (tablespace)
LOCAL STORE IN (tablespace)
(PARTITION [partition
[LOGGING|NOLOGGING]
[TABLESPACE {tablespace|DEFAULT}]
[PCTFREE int]
[PCTUSED int]
[INITRANS int]
[MAXTRANS int]
[STORAGE storage_clause]
[STORE IN {tablespace_name|DEFAULT]
[SUBPARTITION [subpartition [TABLESPACE tablespace]]]])
LOCAL (PARTITION [partition
[LOGGING|NOLOGGING]
[TABLESPACE {tablespace|DEFAULT}]
[PCTFREE int]
[PCTUSED int]
[INITRANS int]
[MAXTRANS int]
[STORAGE storage_clause]
[STORE IN {tablespace_name|DEFAULT]
[SUBPARTITION [subpartition [TABLESPACE tablespace]]]])
GLOBAL PARTITION BY RANGE (col_list)
( PARTITION partition VALUES LESS THAN (value_list)
[LOGGING|NOLOGGING]
[TABLESPACE {tablespace|DEFAULT}]
[PCTFREE int]
[PCTUSED int]
[INITRANS int]
[MAXTRANS int]
[STORAGE storage_clause] )
INDEXTYPE IS indextype [PARALLEL int|NOPARALLEL] [PARAMETERS ('ODCI_Params')]
{Esto es solo para table index, no para bitmap join Index}
Y además index_attribs puede ser cualquier combinación de los siguientes:
NOSORT|SORT
REVERSE
COMPRESS int
NOCOMPRESS
COMPUTE STATISTICS
[NO]LOGGING
ONLINE
TABLESPACE {tablespace|DEFAULT}
PCTFREE int
PCTUSED int
INITRANS int
MAXTRANS int
STORAGE storage_clause
PARALLEL parallel_clause
Si usamos la opcion PARALLEL esta debe estar al final.
create index es una de las pocas sentencias que pueden usar nologging option.
create index requiere un segmento temporal si no hay espacio en memoria suficiente.
Crear indices basados en funciones require que query_rewrite_enabled este a true y query_rewrite_integrity este a trusted.
Un ejemplo de indices basados en funciones para busquedas en mayusculas:
CREATE INDEX idx_case_ins ON my_table(UPPER(empname));
SELECT * FROM my_table WHERE UPPER (empname) = ‘KARL’;
Storage clause
Configuración del almacenamiento de tablas (CREATE TABLE), indices (CREATE INDEX), etc… en oracle.
STORAGE opciones
Opciones:
INITIAL int K | M
NEXT int K | M
MINEXTENTS int
MAXEXTENTS int
MAXEXTENTS UNLIMITED
PCTINCREASE int
FREELISTS int
FREELIST GROUPS int
OPTIMAL
OPTIMAL int K | M
OPTIMAL NULL
BUFFER POOL {KEEP|RECYCLE|DEFAULT}
storage (
initial 65536
next 1048576
minextents 1
maxextents 2147483645
pctincrease 0
freelists 1
freelist groups 1
optimal 7k
buffer_pool default
)
Esta clausula aparece al final de la definición de los objetos de almacenamiento de la base de datos (tablas, indices, etc…).
Cuando creamos un tablespace (CREATE TABLESPACE) podemos definir un storage por defecto para los objetos que se creen dentro de el.
However, a default storage clause can not be specified for locally managed tablespaces. Dictionary managed tablespaces allow to have a storage clause, but without freelists, freelist groups and buffer_pool.
Initial: Especifica el tamaño (en bytes) de la primera extensión.
Next: Especifica el tamaño (en bytes) de la segunda extensión.
Pctincrease: Especifica el % de incremento en el tamaño de las siguientes extensiones.
Especifica el incremento en el tamaño de las siguientes extensiones. El tamaño de una nueva extension es el tamaño de la anterior multiplico por pctincrease. Debe ser 0 para reducir la fragmentación en los tablespaces.
Minextents: Especifica el numero inicial de extensiones cuando se crea el objeto.
Maxextents: Especifica el número máximo de extensiones que el objeto puede tener.
Freelists: Especifica el número de freelists. Este parámetro solo se puede usar con CREATE TABLE or CREATE INDEX.
Freelist groups: Especifica el numero de freelist groups. Este parámetro solo se puede usar con CREATE TABLE or CREATE INDEX.
Buffer_pool: El valor de buffer_pool debe ser uno de: keep, recycle, default. Este parámetro solo se puede usar con CREATE TABLE, CREATE INDEX, CREATE CLUSTER, ALTER TABLE, ALTER INDEX Y ALTER CLUSTER.
Optimal: Solo se puede especificar para los rollback segments.
Create Sequence
Crea un objeto capaz de darnos numeros consecutivos unicos.
CREATE SEQUENCE secuencia
INCREMENT BY n
START WITH n
{MAX VALUE n | NOMAXVALUE}
{MIN VALUE N | NOMINVALUE}
{CYCLE | NOCYCLE}
{CACHE N | NOCACHE}
{ORDER | NOORDER};
En realida es un generador de indentificadores unicos que no bloquea transacciones.
Es muy util para generar primary keys.
Si no nos gusta perder números usamos NOCACHE.
CREATE SEQUENCE S_PROVEEDORES MINVALUE 1 START WITH 1
INCREMENT BY 1 NOCACHE;
Si nos interesa la velocidad:
CREATE SEQUENCE S_PROVEEDORES MINVALUE 1 START WITH 1
INCREMENT BY 1 CACHE 20;
Asi obtenemos el siguiente valor:
SELECT S_PROVEEDORES.NEXTVAL FROM DUAL;
Tambien podemos obtener el valor actual:
SELECT S_PROVEEDORES.CURRVAL FROM DUAL;
Create View
Esta sentencia sirve para crear una vista de una tabla o tablas.
Una vista es una tabla lógica basada en los datos de otra tabla.
Ejemplo:
CREATE VIEW V_PEDIDOS (NUMPEDIDO, FECPEDIDO, NUNCLIENTE, NOMCLIENTE)
FROM
SELECT A.NUMPEDIDO,A.FECPEDIDO,A.NUMCLIENTE, B.NOMCLIENTE
FROM T_PEDIDOS A, T_CLIENTE B
WHERE A.NUMCLIENTE=B.NUMCLIENTE;
Esta vista sacará lo datos de los pedidos con el nombre de cliente.
Al ser lógica no necesita espacio de almacenamiento para los datos. Ademas es instantanea, una vez modificados los datos de las tablas origen, los tenemos disponibles en la vista.
Create Global Temporary Tables
Crea una tabla temporal personal para cada sesion. Eso significa que los datos no se comparten entre sesiones y se eliminan al final de la misma.
CREATE GLOBAL TEMPORARY TABLE tabla_temp (
columna datatype [DEFAULT expr] [column_constraint(s)]
[,columna datatype [,...]]
) {ON COMMIT DELETE ROWS | ON COMMIT PRESERVE ROWS};
Por ejemplo;
CREATE GLOBAL TEMPORARY TABLE tabla_temp (
columna number
) ON COMMIT DELETE ROWS ;
CREATE GLOBAL TEMPORARY TABLE tabla_temp2 (
columna number
) ON COMMIT PRESERVE ROWS ;
Con la opcion ON COMMIT DELETE ROWS se borran los datos cada vez que se hace COMMIT en la sesion.
Con la opcion ON PRESERVE DELETE ROWS los datos no se borran hasta el final de la sesion.
Create materialized view
El SQL de las bases de datos Oracle permite crear vistas materializadas o materialized views. Estas vistas materializadas, a parte de almacenar la definición de la vista propiamente dicha, también almacenan los registros que resultan de la ejecución de la sentencia SELECT que define la vista. Como las vistas normales, la sentencia SELECT es la base de la vista, pero la sentencia SQL se ejecuta cuando se crea la vista y los resultados se almacenan físicamente constituyendo una tabla real que ocupa sitio en el disco duro. Esta tabla puede definirse utilizando los mismos parámetros de almacenamiento que se pueden utilizar para una tabla normal (tablespace, etcétera). Las vistas materializadas también admiten índices, esta funcionalidad resulta muy útil a la hora de mejorar el rendimiento de las sentencias PLSQL o SQL que utilicen vistas materializadas.
Cuando una sentencia SQL o PL/SQL accede a una vista materializada el servidor de la base de datos Oracle, transforma la sentencia dirigiéndose directamente a los datos de la vista que están ya almacenados, en lugar de utilizar los datos de las diferentes tablas utilizadas en la definición de dicha vista.
Evidentemente, si una vista (view) utiliza muchas tablas base enlazadas de forma compleja, y dicha vista va a ser utilizada frecuentemente, será muy conveniente definirla como una vista materializada o materialized view. Esto contribuirá enormemente a mejorar el rendimiento de la base de datos, ya que la sentencia SQL base de la vista sólo se ejecutará una vez.
Por otro lado, está el inconveniente de que si la vista materializada o materialized view va a tener que reutilizarse en el futuro, entonces necesitaremos un mecanismo para actualizar o refrescar dicha vista materializada, ya que las tablas base de la vista pueden haber sufrido modificaciones desde la creación de la misma.
Por todo esto, a la hora de determinar si una vista debe definirse como vista o es mejor definirla como vista materializada, debemos valorar los costes de tener que ejecutar la sentencia SQL base de una vista normal siempre que se acceda a dicha vista, frente a los costes de almacenamiento y actualización de una vista materializada.
Sintaxis del comando SQL utilizado para crear vistas materializadas
CREATE MATERIALIZED VIEW nombre_vistam
[TABLESPACE nombre_ts]
[PARALELL (DEGREE n)]
[BUILD {INMEDIATE|DEFERRED}]
[REFRESH {FAST|COMPLETE|FORCE|NEVER|ON COMMIT}]
[{ENABLE|DISABLE} QUERY REWRITE]
AS SELECT … FROM … WHERE …
Los valores por defecto de las distintas opciones están subrayados.
Si se elige la opción BUILD INMEDIATE, entonces la tabla asociada con la vista materializada se puebla con datos en el momento de la ejecución del comando SQL CREATE. Por el contrario, si se utiliza BUILD DEFERRED, el comando CREATE creará sólo la estructura de la vista, pero la tabla física asociada no se poblará con datos hasta que se realice el primer refresco o actualización de la vista materializada.
La opción REFRESH permite indicar el mecanismo que la base de datos utilizará para refrescar o actualizar la vista materializada. Los diferentes mecanismos y la forma en que una vista materializada o materialized view puede refrescarse, serán objeto de otro artículo en este blog. Como anticipo diré que un refresco completo o COMPLETE, significa que la tabla asociada con la vista materializada se borra completamente, volviéndose a insertar todos los registros devueltos por la ejecución de la sentencia SQL base de la vista, y que un refresco rápido o FAST, significa que la vista materializada se actualiza sólo según hayan sido los cambios realizados sobre las tablas base de la vista desde el último refresco. Para poder utilizar el refresco rápido o FAST, hay que crear previamente los logs de la vista materializada utilizando el comando CREATE MATERIALIZED VIEW LOG.
La opción ENABLE/DISABLE QUERY REWRITE determina si el optimizador Oracle puede o no reescribir las sentencias SQL de manera que, de ser posible, en la fase de ejecución se utilice la vista materializada en lugar de las tablas base de la vista incluidas en la sentencia SQL original. Este es un tema ciertamente complejo y que será objeto de un artículo completo en este blog. Como anticipo indicaré que la reescritura de sentencias SQL sólo está disponible cuando se utiliza el optimizador Oracle basado en costes.
Create Synonym
Crea un sinonimo para algun objeto de la base de datos.
CREATE [OR REPLACE] [PUBLIC] SYNONYM [esquema.]sinonimo
FOR [esquema.]objeto [@dblink]
Con la opción ‘PUBLIC’ se crea un sinonimo público accesible a todos los usuarios, siempre que tengan los privilegios adecuados para el mismo. (ver GRANT)
Sirve para no tener que usar la notación ‘esquema.objeto’ para referirse a un objeto que no es propiedad de usuario.
CREATE PUBLIC SYNONYM T_PEDIDOS FOR PROGRAMADOR.T_PEDIDOS;
No es necesario recompilarlos cuando se redefinen las tablas, de hecho puedes existir sin que exista el objeto al que refererencian.
El acceso es un poco mas eficiente cuando se accede por sinonimos públicos.
Cuando en una sentencia no citamos el nombre del esquema, Oracle resuelve los nombres en el siguiente orden:
- usuario actual
- private synonym
- public synonym
Tambien podemos usarlo para cambiar el objeto que usamos sin tener que cambiar la programacion.
Asi cambiamos la tabla:
CREATE PUBLIC SYNONYM T_PEDIDOS FOR PROGRAMADOR.T_PEDIDOS_PRUEBA;
Create User
Esta sentencia sirve para crear un usuario oracle.
Un usuario es un nombre de acceso a la base de datos oracle. Normalmente va asociado a una clave (password).
Lo que puede hacer un usuario una vez ha accedido a la base de datos depende de los permisos que tenga asignados ya sea directamente (GRANT) como sobre algun rol que tenga asignado (CREATE ROLE).
El perfil que tenga asignado influye en los recursos del sistema de los que dispone un usuario a la hora de ejecutar oracle (CREATE PROFILE).
La sintaxis es:
CREATE USER username
IDENTIFIED {BY password | EXTERNALLY | GLOBALLY AS ‘external_name’}
options;
Donde options:
DEFAULT TABLESPACE tablespace
TEMPORARY TABLESPACE tablespace
QUOTA int {K | M} ON tablespace
QUOTA UNLIMITED ON tablespace
PROFILE profile_name
PASSWORD EXPIRE
ACCOUNT {LOCK|UNLOCK}
Alterar un usuario
ALTER USER NOMBRE_USUARIO
IDENTIFIED BY CLAVE _ACCESO
[DEFAULT TABLESPACE ESPACIO_TABLA]
[TEMPORARY TABLESPACE ESPACIO_TABLA]
[QUOTA {ENTERO {K | M } | UNLIMITED } ON ESPACIO_TABLA
[PROFILE PERFIL];
Crea un usuario sin derecho a guardar datos o crear objetos:
CREATE USER usuariolimitado IDENTIFIED BY miclavesecreta;
Crea un usuario con todos los derechos para guardar datos o crear objetos:
DROP USER miusuario CASCADE;
CREATE USER miusuario IDENTIFIED BY miclavesecreta
DEFAULT TABLESPACE data
TEMPORARY TABLESPACE temp
QUOTA UNLIMITED ON data;
CREATE ROLE programador;
GRANT CREATE session, CREATE table, CREATE view,
CREATE procedure,CREATE synonym,
ALTER table, ALTER view, ALTER procedure,ALTER synonym,
DROP table, DROP view, DROP procedure,DROP synonym,
TO conn;
GRANT programador TO miusuario;
Es neceario crear el usuario antes de asignar permisos con GRANT o un ROLE por defecto.
Create Role
Esta sentencia sirve para crear un rol de usuario.
Un rol es una forma de agrupar permisos (o privilegios) para asignarlos luego a los usuarios.
Cada usuario puede tener varios roles.
Ejemplo de creación de un rol:
CREATE ROLE MI_PROPIO_ROLE
Crea un rol sin password:
CREATE ROLE role NOT IDENTIFIED
Crea un rol con password:
CREATE ROLE role IDENTIFIED BY password
Crea un rol de aplicación:
CREATE ROLE role IDENTIFIED USING [schema.]package
Crea un rol basado en uno del S.O.:
ALTER ROLE role IDENTIFIED EXTERNALLY
Crea un rol basado en el servicio de directorio:
ALTER ROLE role IDENTIFIED GLOBALLY
Ejemplo para crear un script que asigna todos los permisos de actual esquema
SELECT decode(object_type,
‘TABLE’,'GRANT SELECT, INSERT, UPDATE, DELETE , REFERENCES ON’||&OWNER||’.',
‘VIEW’,'GRANT SELECT ON ‘||&OWNER||’.',
‘SEQUENCE’,'GRANT SELECT ON ‘||&OWNER||’.',
‘PROCEDURE’,'GRANT EXECUTE ON ‘||&OWNER||’.',
‘PACKAGE’,'GRANT EXECUTE ON ‘||&OWNER||’.',
‘FUNCTION’,'GRANT EXECUTE ON’||&OWNER||’.’ )||object_name||’ TO MI_PROPIO_ROLE ;’
FROM user_objects
WHERE
OBJECT_TYPE IN ( ‘TABLE’, ‘VIEW’, ‘SEQUENCE’, ‘PROCEDURE’, ‘PACKAGE’,'FUNCTION’)
ORDER BY OBJECT_TYPE
Create profile
Esta sentencia sirve para crear un perfil de usuario.
Un perfil de usuario es una forma de limitar los recursos que puede utilizar un usuario.
Cada usuario puede tener un único perfil.
Antes de asignar un perfil a un usuario es necesario que este perfil exista en la base de datos.
Un perfil se asigna en la creación de un usuario CREATE USER o modificandolo ALTER USER.
Un ejemplo de script sería:
CREATE PROFILE app_user LIMIT
SESSIONS_PER_USER 2 –
CPU_PER_SESSION 10000 — decimas de segundo
CPU_PER_CALL 1 — decimas de segundo
CONNECT_TIME UNLIMITED — minutos
IDLE_TIME 30 — minutos
LOGICAL_READS_PER_SESSION DEFAULT — DB BLOCKS
LOGICAL_READS_PER_CALL DEFAULT — DB BLOCKS
— COMPOSITE_LIMIT DEFAULT –
PRIVATE_SGA 20M –
FAILED_LOGIN_ATTEMPTS 3 –
PASSWORD_LIFE_TIME 30 — dias
PASSWORD_REUSE_TIME 12 –
PASSWORD_REUSE_MAX UNLIMITED –
PASSWORD_LOCK_TIME DEFAULT — dias
PASSWORD_GRACE_TIME 2 — dias
PASSWORD_VERIFY_FUNCTION NULL;
Los recursos que limitamos son recursos del kernel: uso de la CPU, duración de sesion,…
Y tambien limites de uso de las claves de acceso (passwords): duración, intentos de acceso, reuso, …
Por ejemplo:
ALTER PROFILE default LIMIT IDLE_TIME 20;
Limita el perfil por defecto a 20 minutos. IDLE_TIME: Es el tiempo que puede estar una sesión sin hacer nada antes de ser cerrada.
Drop
Utilice Dop para mover objetos a la papelera de reciclaje de Oracle:
Ejemplos:
Borrar una tabla:
DROP TABLE [schema.]table [CASCADE CONSTRAINTS] [PURGE];
Borrar una Funcion:
DROP FUNCTION [schema.]function
Borrar un índice:
DROP INDEX [schema.]index [FORCE]
FORCE se puede utilizar para borrar índices que estas siendo utilizados
Borrar una vista materializada:
DROP MATERIALIZED VIEW [schema.] materialized_view
Borrar un log de vista materializada:
DROP MATERIALIZED VIEW LOG ON [schema.]table;
Borrar un paquete:
DROP PACKAGE [BODY] [schema.]package_name;
Borrar un procedimiento:
DROP PROCEDURE [schema.]procedure_name
Borrar un perfil:
DROP PROFILE profile_name [CASCADE]
Si un usuario esta asociado a un profile, esté no puede ser borrado, utilice CASCADE para desasignar antes los profiles de los usuarios.
Borrar un rol:
DROP ROLE role
Borrar un segmento:
DROP ROLLBACK SEGMENT rbs_name
Borrar una secuencia:
DROP SEQUENCE [schema.]sequence_name
Borrar un sinonimo:
DROP [PUBLIC] SYNONYM [schema.]synonym [FORCE]
Borrar un espacio de tablas:
DROP TABLESPACE tablespace_name [INCLUDING CONTENTS [AND DATAFILES]
[CASCADE CONSTRAINTS]];
Borrar un disparador:
DROP TRIGGER [schema.]trigger
Borrar un usuario:
DROP USER username [CASCADE]
Borrar una vista:
DROP VIEW [schema.]view [CASCADE CONSTRAINTS]
Alter table
Sirve para cambiar la definición de una tabla. Podemos cambiar tanto columnas como restricciones (ver CONSTRAINTS).
La sintaxis es:
ALTER TABLE [esquema.]tabla {ADD|MODIFY|DROP}…
Añadir una columna a una tabla:
ALTER TABLE T_PEDIDOS ADD TEXTOPEDIDO Varchar2(35);
Cambiar el tamaño de una columna en una tabla:
ALTER TABLE T_PEDIDOS MODIFY TEXTOPEDIDO Varchar2(135);
Hacer NOT NULL una columna en una tabla:
ALTER TABLE T_PEDIDOS MODIFY (TEXTOPEDIDO NOT NULL);
Eliminar una columna a una tabla:
ALTER TABLE T_PEDIDOS DROP COLUMN TEXTOPEDIDO;
Valor por defecto de una columna:
ALTER TABLE T_PEDIDOS MODIFY TEXTOPEDIDO Varchar2(135) DEFAULT ‘ABC…’;
Añade dos columnas:
ALTER TABLE T_PEDIDOS
ADD (SO_PEDIDOS_ID INT, TEXTOPEDIDO Varchar2(135));
Tipos de Constraints
Clave primaria
La clave primaria se utiliza para identificar en forma única cada línea en la tabla. Puede ser parte de un registro real, o puede ser un campo artificial (uno que no tiene nada que ver con el registro real). Una clave primaria puede consistir en uno o más campos en una tabla. Cuando se utilizan múltiples campos como clave primaria, se los denomina claves compuestas.
Las claves primarias pueden especificarse cuando se crea la tabla (utilizando CREATE TABLE) o cambiando la estructura existente de la tabla (utilizando ALTER TABLE).
Ejemplo para la especificación de una clave primaria cuando se crea una tabla:
CREATE TABLE CLIENTES
(SID integer PRIMARY KEY,
Last_Name varchar(30),
First_Name varchar(30));
A continuación se presentan ejemplos para la especificación de una clave primaria al modificar una tabla:
LTER TABLE CLIENTES ADD PRIMARY KEY (SID);
Clave externa
Una clave externa es un campo (o campos) que señala la clave primaria de otra tabla. El propósito de la clave externa es asegurar la integridad referencial de los datos. En otras palabras, sólo se permiten los valores que se esperan que aparezcan en la base de datos.
Por ejemplo, digamos que tenemos dos tablas, una tabla CLIENTES que incluyen todos los datos del CLIENTES, y la tabla ÓRDENES que incluye los pedidos de CLIENTES.
La restricción aquí es que todos los pedidos deben asociarse con un CLIENTES que ya se encuentra en la tabla CUSTOMER. En este caso, colocaremos una clave externa en la tabla ÓRDENES y la relacionaremos con la clave primaria de la tabla CLIENTES. De esta forma, nos aseguramos que todos los pedidos en la tabla ÓRDENES estén relacionadas con un CLIENTES en la tabla CLIENTES. En otras palabras, la tabla ÓRDENES no puede contener información de un CLIENTES que no se encuentre en la tabla CLIENTES.
La estructura de estas dos tablas será la siguiente:
Tabla CLIENTES
|
nombre de columna |
característica |
|
SID |
Clave Primaria |
|
Last_Name |
|
|
First_Name |
|
Tabla ÓRDENES
|
nombre de columna |
característica |
|
Order_ID |
Clave Primaria |
|
Order_Date |
|
|
Customer_SID |
Clave Externa |
|
Amount |
|
En el ejemplo anterior, la columna Customer_SID en la tabla ORDENES es una clave externa señalando la columna SID en la tabla CLIENTES.
Ejemplo de cómo especificar la clave externa a la hora de crear la tabla ÓRDENES:
CREATE TABLE ORDENES
(Order_ID integer primary key,
Order_Date date,
Customer_SID integer references CLIENTES (SID),
Amount double);
Ejemplo para la especificación de una clave externa al modificar una tabla: Esto asume que se ha creado la tabla ORDERS, y que la clave externa todavía no se ha ingresado:
ALTER TABLE ORDENES
ADD (CONSTRAINT fk_orders1) FOREIGN KEY (customer_sid) REFERENCES CLIENTES (SID);
NOT NULL
En forma predeterminada, una columna puede ser NULL. Si no desea permitir un valor NULL en una columna, querrá colocar una restricción en esta columna especificando que NULL no es ahora un valor permitido.
Por ejemplo, en la siguiente instrucción,
CREATE TABLE clientes
(SID integer NOT NULL,
Last_Name varchar (30) NOT NULL,
First_Name varchar(30));
Las columnas “SID” y “Last_Name” no incluyen NULL, mientras que “First_Name” puede incluir NULL.
UNIQUE
La restricción UNIQUE asegura que todos los valores en una columna sean distintos.
Por ejemplo, en la siguiente instrucción,
CREATE TABLE clientes
(SID integer Unique,
Last_Name varchar (30),
First_Name varchar(30));
La columna “SID” no puede incluir valores duplicados, mientras dicha restricción no se aplica para columnas “Last_Name” y “First_Name”.
Por favor note que una columna que se especifica como clave primaria también puede ser única. Al mismo tiempo, una columna que es única puede o no ser clave primaria.
CHECK
La restricción CHECK asegura que todos los valores en una columna cumplan ciertas condiciones.
Por ejemplo, en la siguiente instrucción,
CREATE TABLE clientes
(SID integer CHECK (SID > 0),
Last_Name varchar (30),
First_Name varchar(30));
La columna “SID” sólo debe incluir enteros mayores a 0.
Por favor note que la restricción CHECKno sea ejecutada por MySQL en este momento.
Modificar Constraints
Para cambiar las restricciones y la clave primaria de una tabla debemos usar ALTER TABLE.
Crear una clave primaria (primary key):
ALTER TABLE T_PEDIDOS ADD CONSTRAINT PK_PEDIDOS
PRIMARY KEY (numpedido,lineapedido);
Crear una clave externa, para integridad referencial (foreign key):
ALTER TABLE T_PEDIDOS ADD CONSTRAINT FK_PEDIDOS_CLIENTES
FOREIGN KEY (codcliente) REFERENCES T_CLIENTES (codcliente));
Crear un control de valores (check constraint):
ALTER TABLE T_PEDIDOS ADD CONSTRAINT CK_ESTADO
CHECK (estado IN (1,2,3));
Crear una restricción UNIQUE:
ALTER TABLE T_PEDIDOS ADD CONSTRAINT UK_ESTADO
UNIQUE (correosid);
Normalmente una restricción de este tipo se implementa mediante un indice unico (ver CREATE INDEX).
Borrar una restricción:
ALTER TABLE T_PEDIDOS DROP CONSTRAINT CON1_PEDIDOS;
Deshabilita una restricción:
ALTER TABLE T_PEDIDOS DISABLE CONSTRAINT CON1_PEDIDOS;
Habilita una restricción:
ALTER TABLE T_PEDIDOS ENABLE CONSTRAINT CON1_PEDIDOS;
La sintaxis ALTER TABLE para restricciones es:
ALTER TABLE [esquema.]tabla
constraint_clause,…
[ENABLE enable_clause | DISABLE disable_clause]
[{ENABLE|DISABLE} TABLE LOCK]
[{ENABLE|DISABLE} ALL TRIGGERS];
Donde constraint_clause puede ser alguna de las siguientes entradas:
ADD out_of_line_constraint(s)
ADD out_of_line_referential_constraint
DROP PRIMARY KEY [CASCADE] [{KEEP|DROP} INDEX]
DROP UNIQUE (column,…) [{KEEP|DROP} INDEX]
DROP CONSTRAINT constraint [CASCADE]
MODIFY CONSTRAINT constraint constrnt_state
MODIFY PRIMARY KEY constrnt_state
MODIFY UNIQUE (column,…) constrnt_state
RENAME CONSTRAINT constraint TO new_name
Donde a su vez constrnt_state puede ser:
[[NOT] DEFERRABLE] [INITIALLY {IMMEDIATE|DEFERRED}]
[RELY | NORELY] [USING INDEX using_index_clause]
[ENABLE|DISABLE] [VALIDATE|NOVALIDATE]
[EXCEPTIONS INTO [schema.]table]
Borrar una restricción:
ALTER TABLE T_PEDIDOS DROP CONSTRAINT CON1_PEDIDOS;
Truncate
Quita todas las filas de una tabla sin registrar las eliminaciones individuales de filas. TRUNCATE TABLE es similar a la instrucción DELETE sin una cláusula WHERE; no obstante, TRUNCATE TABLE es más rápida y utiliza menos recursos de registros de transacciones y de sistema.
TRUNCATE TABLE [esquema.]tabla
[{PRESERVE|PURGE} MATERIALIZED VIEW LOG]
[{DROP | REUSE} STORAGE]
TRUNCATE CLUSTER [esquema.]cluster
[{DROP | REUSE} STORAGE]
La instrucción Truncate no necesita “Commit”
La instrucción trúncate libera el espacio utilizado por los datos de la tabla.
Rename
Cambia el nombre a una tabla, vista, secuencia o sinonimo privado.
RENAME old TO new
Lenguaje de manipulación de datos (DML)
Un lenguaje de manipulación de datos (Data Manipulation Language, o DML en inglés) es un lenguaje proporcionado por el sistema de gestión de base de datos que permite a los usuarios de la misma llevar a cabo las tareas de consulta o manipulación de los datos, organizados por el modelo de datos adecuado.
El lenguaje de manipulación de datos más popular hoy día es SQL, usado para recuperar y manipular datos en una base de datos relacional. Otros ejemplos de DML son los usados por bases de datos IMS/DL1, CODASYL u otras.
SELECT
La selección sobre una tabla consiste en elegir un subconjunto de filas que cumplan (o no) algunas condiciones determinadas. La sintaxis de una sentencia de este tipo es la siguiente:
SELECT */ columna1, columna2,….
FROM nombre-tabla
[WHERE condición]
[GROUP BY columna1, columna2.... ]
[HAVING condición-selección-grupos ]
[ORDER BY columna1 [DESC], columna2 [DESC]… ]
Si ejecutamos:
SELECT * FROM T_PEDIDOS;
Nos da la salida:
COD_PEDIDO NOMBRE ESTADO
————————————————-
1 JUAN 0
2 ANTONIO 1
3 PEPE 0
…
* / columna1, columna2,…. Si se escribe *, selecciona todas las columnas. Si se desea seleccionar sólo algunas columnas de la tabla, se debe poner los nombres de cada una de ellas, separadas por una coma.
nombre-tabla Nombre de la(s) tabla(s) de la(s) cual(es) se van a seleccionar los valores.
GROUP BY columna1, columna2….
Se utiliza para agrupar resultados por una determinada columna, específicamente cuando se utilizan funciones de columna y los resultados se desean obtener por grupos (SQL lanza un sort para generar los grupos).
HAVING condición-selección-grupos
Se utiliza con la cláusula “GROUP BY”, cuando se quiere poner condiciones al resultado de un grupo.
ORDER BY colum1 [DESC], colum2 [DESC...]
Sirve para ordenar el resultado. Todas las columnas por las que se desee realizar el orden tienen que encontrarse en la sentencia “Select” de la consulta. El orden de las columnas puede ser ascendente, (por omisión, ASC), o descendente, (DESC).
SENTENCIA SELECT (JOIN)
Consiste en la unión de campos de dos o más tablas. Dichas tablas tendrán por lo menos una columna común que sirva de nexo del join.
SELECT columna1, columna2,…
FROM nombre-tabla1, nombre-tabla2
columna1, columna2,… Para diferenciar las columnas con el mismo nombre se antepondrá el nombre de la tabla a la que pertenecen, utilizando el punto como separador. Por ejemplo:
SELECT Tabla1.Columna2, Tabla2.Columna2, Columna3…..
FROM Tabla1, Tabla2
WHERE Tabla1.Columna1 = Tabla2.Columna1
La Columna1 de cada una de las tablas respectivas son las columnas de nexo o columnas de join.
SENTENCIA SELECT DISTINCT
Recupera las filas de una tabla eliminando los valores de la columna duplicados.
SELECT DISTINCT columna1, columna2,….
FROM nombre-tabla1, nombre-tabla2
[GROUP BY columna1, columna2....]
[HAVING condición-selección-grupos]
[ORDER BY columna1 [DESC], columna2 [DESC]…
SENTENCIA SELECT TOP N FILAS DE UNA TABLA
En Oracle8i podemos usar la sintaxis siguiente, con una cláusula ORDER BY, para elegir filas con los valores máximos o mínimos de un campo:
SELECT *
FROM (SELECT * FROM my_table ORDER BY col_name_1 DESC)
WHERE ROWNUM < 10;
FUNCIONES SOBRE COLUMNAS
COUNT. Indica el número de filas que cumplen una determinada condición, o el número de valores diferentes que posee una columna.
COUNT(*) o COUNT(DISTINCT columna)
SUM. Suma los valores de una columna.
SUM(columna)
AVG. Entrega la media de los valores de una columna.
AVG(columna)
MIN. Entrega el valor mínimo de una columna.
MIN(columna)
MAX. Entrega el valor máximo de una columna.
MAX(columna)
SUBSELECTS
Permite realizar comparaciones con valores obtenidos en otra sentencia select anidada, a la que se denomina “Subselect” o “Subselect interna”.
SELECT columna1>, columna2,….
FROM nombre-tabla1, nombre-tabla2
WHERE columna1 = (SELECT columna1
FROM nombre-tabla1, nombre-tabla2
WHERE condición)
(Cuando en la condición se pone el operador =, la subselect deberá recuperar un sólo registro).
Insert
Una sentencia INSERT de SQL agrega uno o más registros a una (y sólo una) tabla en una base de datos relacional.
Forma básica
INSERT
INTO
”tabla”
(”columna1”, [''columna2,... ''])
VALUES
(”valor1”, [''valor2,...''])
Las cantidades de columnas y valores deben ser las mismas. Si una columna no se especifica, le será asignado el valor por omisión. Los valores especificados (o implícitos) por la sentencia INSERT deberán satisfacer todas las restricciones aplicables. Si ocurre un error de sintaxis o si alguna de las restricciones es violada, no se agrega la fila y se devuelve un error.
Ejemplo
INSERT
INTO agenda_telefonica (nombre, numero)
VALUES
(‘Roberto Jeldrez’, ’4886850′);
Cuando se especifican todos los valores de una tabla, se puede utilizar la sentencia acortada:
INSERT
INTO
”tabla”
VALUES
(”valor1”, [''valor2,...''])
Ejemplo (asumiendo que ‘nombre’ y ‘número’ son las únicas columnas de la tabla ‘agenda_telefonica’):
INSERT
INTO agenda_telefonica VALUES
(‘Roberto Jeldrez’, ’4886850′);
Formas Avanzadas:Inserciones en múltiples filas
Una característica de SQL (desde SQL-92) es el uso de constructores de filas para insertar múltiples filas a la vez, con una sola sentencia SQL:
INSERT
INTO
”tabla”
(”columna1”, [''columna2,... ''])
VALUES
(”valor1a”, [''valor1b,...'']), (”value2a”, [''value2b,...'']),…
Ejemplo (asumiendo ese ‘nombre’ y ‘número’ son las únicas columnas en la tabla ‘agenda_telefonica’):
INSERT
INTO agenda_telefonica VALUES
(‘Roberto Fernández’, ’4886850′), (‘Alejandro Sosa’, ’4556550′);
Que podía haber sido realizado por las sentencias
INSERT
INTO agenda_telefonica VALUES
(‘Roberto Fernández’, ’4886850′);
INSERT
INTO agenda_telefonica VALUES
(‘Alejandro Sosa’, ’4556550′);
Notar que las sentencias separadas pueden tener semántica diferente (especialmente con respecto a los triggers), y puede tener diferente rendimiento que la sentencia de inserción múltiple.
Para insertar varias filas en MS SQL puede utilizar esa construcción:
INSERT
INTO phone_book
SELECT
‘John Doe’, ’555-1212′
UNION ALL
SELECT
‘Peter Doe’, ’555-2323′;
Tenga en cuenta que no se trata de una sentencia SQL válida de acuerdo con el estándar SQL (SQL: 2003), debido a la cláusula subselect incompleta.
Para hacer lo mismo en Oracle se usa DUAL TABLE, siempre que se trate de solo una simple fila:
INSERT
INTO phone_book
SELECT
‘John Doe’, ’555-1212′
FROM DUAL
UNION ALL
SELECT
‘Peter Doe’,’555-2323′
FROM DUAL
Un estándar-conforme implementación de esta lógica se muestra el siguiente ejemplo, o como se muestra arriba:
INSERT
INTO phone_book
SELECT
‘John Doe’, ’555-1212′
FROM LATERAL (
VALUES
(1)
)
AS t(c)
UNION ALL
SELECT
‘Peter Doe’,’555-2323′
FROM LATERAL (
VALUES
(1)
)
AS t(c)
Formas Avanzadas: Insertando filas con valores nulos
Método Implícito: Se omiten las columnas que aceptan valores nulos.
SQL> insert into
2 departments(department_id, department_name)
3 values(301, ‘Departamento 301′);
1 row created.
SQL> commit;
Commit complete.
Método Explicito: Especificamos la palabra clave NULL en las columnas donde queremos insertar un
valor nulo.
SQL> insert into departments
2 values(302, ‘Departamento 302′, NULL, NULL);
1 row created.
SQL> commit;
Commit complete.
Formas Avanzadas: Insertando valores especiales
SQL> insert into employees (employee_id,
2 first_name, last_name,
3 email, phone_number,
4 hire_date, job_id, salary,
5 commission_pct, manager_id,
6 department_id)
7 values(250,
8 ‘Gustavo’, ‘Coronel’,
9 ‘gcoronel@miempresa.com’, ’511.481.1070′,
10 sysdate, ‘FI_MGR’, 14000,
11 NULL, 102, 100);
1 row created.
SQL> commit;
Commit complete.
Formas Avanzadas: Insertando valores específicos de fechas
SQL> insert into employees
2 values(251, ‘Ricardo’, ‘Marcelo’,
3 ‘rmarcelo@techsoft.com’, ’511.555.4567′,
4 to_date(‘FEB 4, 2005′, ‘MON DD, YYYY’),
5 ‘AC_ACCOUNT’, 11000, NULL, 100, 30);
1 row created.
SQL> commit;
Commit complete.
Formas Avanzadas: Usando & Para el ingreso de valores
SQL> insert into
2 departments (department_id, department_name, location_id)
3 values (&department_id, ‘&department_name’, &location_id);
Enter value for department_id: 3003
Enter value for department_name: Departamento 303
Enter value for location_id: 2800
old 3: values (&department_id, ‘&department_name’, &location_id)
new 3: values (3003, ‘Departamento 303′, 2800)
1 row created.
SQL> commit;
Commit complete.
Formas Avanzadas: Copiando desde otra tabla
SQL> create table test
2 (
3 id number(6) primary key,
4 name varchar2(20),
5 salary number(8,2)
6 );
Table created.
SQL> insert into test (id, name, salary)
2 select employee_id, first_name, salary
3 from employees
4 where department_id = 30;
7 rows created.
SQL> commit;
Commit complete.
Formas Avanzadas: Insertando en multiples tablas
Primero creamos las siguientes tablas: test50 y test80.
SQL> create table test50
2 (
3 id number(6) primary key,
4 name varchar2(20),
5 salary number(8,2)
6 );
Table created.
SQL> create table test80
2 (
3 id number(6) primary key,
4 name varchar2(20),
5 salary number(8,2)
6 );
Table created.
Luego limpiamos la tabla test.
SQL> delete from test;
rows deleted.
SQL> commit;
Commit complete.
Ahora procedemos a insertar datos en las tres tablas a partir de la tabla employees.
SQL> insert all
2 when department_id = 50 then
3 into test50 (id, name, salary)
4 values(employee_id, first_name, salary)
5 when department_id = 80 then
6 into test80 (id, name, salary)
7 values (employee_id, first_name, salary)
8 else
9 into test(id, name, salary)
10 values(employee_id, first_name, salary)
11 select department_id, employee_id, first_name, salary
12 from employees;
109 rows created.
SQL> commit;
Commit complete.
Update
Una sentencia UPDATE de SQL es utilizada para modificar los valores de un conjunto de registros existentes en una tabla.
Forma básica
UPDATE
”tabla”
SET
”columna1” = ”valor1”
[,''columna2'' = ''valor2'',...]
WHERE
”columnaN = ”valorN”
Ejemplo
UPDATE My_table SET field1 = ‘updated value’
WHERE field2 = ‘N’;
Actualizando una Columna de una Tabla
Incrementar el salario de todos los empleados en 10%.
SQL> update employees
2 set salary = salary * 1.10;
109 rows updated.
SQL> Commit;
Commit complete.
Seleccionando las Filas a Actualizar
Ricardo Marcelo (Employee_id=251) ha sido trasladado de departamento de Compras (Department_id = 30) al departamento de Ventas (Department_id = 80).
SQL> select employee_id, first_name, department_id, salary
2 from employees
3 where employee_id = 251;
EMPLOYEE_ID FIRST_NAME DEPARTMENT_ID SALARY
———– ——————– ————- ———-
251 Ricardo 30 12100
SQL> update employees
2 set department_id = 80
3 where employee_id = 251;
1 row updated.
SQL> select employee_id, first_name, department_id, salary
2 from employees
3 where employee_id = 251;
EMPLOYEE_ID FIRST_NAME DEPARTMENT_ID SALARY
———– ——————– ————- ———-
251 Ricardo 80 12100
SQL> commit;
Commit complete.
Actualizando Columnas con Subconsultas
Gustavo Coronel (Employee_id = 250) ha sido trasladado al mismo departamento del empleado 203, y su salario tiene que ser el máximo permitido en su puesto de trabajo.
SQL> select employee_id, first_name, last_name, department_id, job_id, salary
2 from employees
3 where employee_id = 250;
EMPLOYEE_ID FIRST_NAME LAST_NAME DEPARTMENT_ID JOB_ID SALARY
———– ————— ————— ————- ———- ———-
250 Gustavo Coronel 100 FI_MGR 15400
SQL> update employees
2 set department_id = (select department_id from employees
3 where employee_id = 203),
4 salary = (select max_salary from jobs
5 where jobs.job_id = employees.job_id)
6 where employee_id = 250;
1 row updated.
SQL> commit;
Commit complete.
SQL> select employee_id, first_name, last_name, department_id, job_id, salary
2 from employees
3 where employee_id = 250;
EMPLOYEE_ID FIRST_NAME LAST_NAME DEPARTMENT_ID JOB_ID SALARY
———– ————— ————— ————- ———- ———-
250 Gustavo Coronel 40 FI_MGR 16000
Actualizando Varias Columnas con una Subconsulta
Asumiremos que tenemos la tabla resumen_dept, con la siguiente estructura:
| Columna |
Tipo Dato |
Nulos |
Descripcion |
| Department_id |
Number(4) |
No |
Código de Departamento. |
| Emps |
Number(4) |
Si |
Cantidad de Empleados en el departamento. |
| Planilla |
Number(10,2) |
Si |
Emporte de la planilla en el departamento. |
Esta tabla guarda la cantidad de empleados y el importe de la planilla por departamento.
Este script crea la tabla resumen_det e inserta los departamentos.
SQL> create table resumen_dept
2 (
3 department_id number(4) primary key,
4 emps number(4),
5 planilla number(10,2)
6 );
Table created.
SQL> insert into resumen_dept (department_id)
2 select department_id from departments;
31 rows created.
SQL> commit;
Commit complete.
Este script actualiza la tabla resumen_dept.
SQL> update resumen_dept
2 set (emps, planilla) = (select count(*), sum(salary)
3 from employees
4 where employees.department_id = resumen_dept.department_id);
31 rows updated.
SQL> commit;
Commit complete.
Error de Integridad Referencial
SQL> update employees
2 set department_id = 55
3 where department_id = 110;
update employees
*
ERROR at line 1:
ORA-02291: integrity constraint (HR.EMP_DEPT_FK) violated – parent key not found
Delete
Una sentencia DELETE de SQL borra cero o más registros existentes en una tabla,
Forma básica
DELETE
FROM
”tabla”
WHERE
”columna1” = ”valor1”
Ejemplo
DELETE
FROM My_table WHERE field2 = ‘N’;
Eliminar Todas la Filas de una Tabla
SQL> select count(*) from test;
COUNT(*)
———-
30
SQL> delete from test;
30 rows deleted.
SQL> commit;
Commit complete.
SQL> select count(*) from test;
COUNT(*)
———-
0
Seleccionando las Filas a Eliminar
Creando una tabla de prueba
SQL> create table copia_emp
2 as select * from employees;
Table created.
Eliminando una sola fila
SQL> delete from copia_emp
2 where employee_id = 190;
1 row deleted.
SQL> commit;
Commit complete.
Eliminando un grupo de filas
SQL> delete from copia_emp
2 where department_id = 50;
44 rows deleted.
SQL> commit;
Commit complete.
Eliminar los empleados que tienen el salario máximo en cada puesto de trabajo.
SQL> delete from copia_emp
2 where salary = (select max_salary from jobs
3 where jobs.job_id = copia_emp.job_id);
1 row deleted.
SQL> commit;
Commit complete.
Error de Integridad Referencial
SQL> delete from departments
2 where department_id = 50;
delete from departments
*
ERROR at line 1:
ORA-02292: integrity constraint (HR.EMP_DEPT_FK) violated – child record found
Lenguaje de control de datos (DCL)
Grant
Grant (dar permisos)
Esta sentencia sirve para dar permisos (o privilegios) a un usuario o a un rol.
Un permiso, en oracle, es un derecho a ejecutar una sentencia (system privileges) o a acceder a un objeto de otro usuario (object privileges).
La sintaxis es:
GRANT <ROL> TO <URUARIO / ROL/public > [WITH GRANT OPTION]
La opcion WITH GRANT OPTION otorga al usuario la posibilidad de otorgar el rol a otro usuario o rol.
El conjunto de permisos es fijo, esto quiere decir que no se pueden crear nuevos tipos de permisos.
Si un permiso se asigna a rol especial PUBLIC significa que puede ser ejecutado por todos los usuarios.
Permisos para acceder a la base de datos (permiso de sistema):
GRANT CREATE SESSION TO miusuario;
Permisos para usuario de modificación de datos (permiso sobre objeto):
GRANT SELECTS, INSERT, UPDATE, DELETE ON T_PEDIDOS TO miusuario;
Permisos de solo lectura para todos:
GRANT SELECT ON T_PEDIDOS TO PUBLIC;
Permisos de sistema (system privileges)
Los permisos del sistema pueden ser:
CREATE SESSION – Permite conectar a la base de datos
UNLIMITED TABLESPACE – Uso de espacio ilimitado del tablespace.
SELECT ANY TABLE – Consultas en tables, views, or mviews en cualquier esquema
UPDATE ANY TABLE – Actualizar filas en tables and views en cualquier esquema
INSERT ANY TABLE – Insertar filas en tables and views en cualquier esquema
Permisos de administrador para CREATE, ALTER o DROP:
Cluster, context, database, link, dimension, directory, index,
materialized view, operator, outline, procedure, profile, role,
rollback segment, sequence, session, synonym, table, tablespace,
trigger, type, user, view.
Los roles predefindos son:
SYSDBA, SYSOPER, OSDBA, OSOPER, EXP_FULL_DATABASE, IMP_FULL_DATABASE, SELECT_CATALOG_ROLE, EXECUTE_CATALOG_ROLE, DELETE_CATALOG_ROLE, AQ_USER_ROLE, AQ_ADMINISTRATOR_ROLE – manejo de la cola
SNMPAGENT – Agente inteligente.
RECOVERY_CATALOG_OWNER – rman
HS_ADMIN_ROLE – servicios heterogeneos
Los roles CONNECT, RESOURCE y DBA ya no deben usarse (aunque estan soportados).
Permisos sobre objetos (object privileges)
Los permisos sobre objetos mas importantes son: SELECT, UPDATE, INSERT, DELETE, ALTER, DEBUG, EXECUTE, INDEX, REFERENCES
GRANT object_priv [(column, column,...)]
ON [schema.]object
TO {user, | role, |PUBLIC} [WITH GRANT OPTION] [WITH HIERARCHY OPTION]
GRANT ALL PRIVILEGES [(column, column,...)]
ON [schema.]object
TO {user, | role, |PUBLIC} [WITH GRANT OPTION] [WITH HIERARCHY OPTION]
GRANT object_priv [(column, column,...)]
ON DIRECTORY directory_name
TO {user, | role, |PUBLIC} [WITH GRANT OPTION] [WITH HIERARCHY OPTION]
GRANT object_priv [(column, column,...)]
ON JAVA [RE]SOURCE [schema.]object
TO {user, | role, |PUBLIC} [WITH GRANT OPTION] [WITH HIERARCHY OPTION]
Con la opcion WITH HIERARCHY OPTION damos permisos sobre todos los subojetos, incluso sobre los que se creen despues de ejecutar el GRANT.
Con la opción WITH GRANT OPTION damos permiso para que el que los recibe los pueda a su vez asignar a otros usuarios y roles.
La opción “GRANT ALL PRIVILEGES…” se puede escribir tambien como “GRANT ALL…”
Podemos obtener la lista de permisos de las tablas asi:
SELECT * FROM ALL_TAB_PRIVS_MADE;
Es posible asignar varios Object_Privs en un solo comando GRANT.
GRANT SELECT (empno), UPDATE (sal) ON pepe.tabla TO miusuario
Permisos del rol SYSDBA:
CREATE DATABASE
CREATE SPFILE
STARTUP and SHUTDOWN
ALTER DATABASE: open, mount, back up, or change character set
ARCHIVELOG and RECOVERY
Includes the RESTRICTED SESSION privilege
Permisos del rol SYSOPER:
CREATE SPFILE
STARTUP and SHUTDOWN
ALTER DATABASE: open, mount, back up
ARCHIVELOG and RECOVERY
Includes the RESTRICTED SESSION privilege
Cada tipo de objeto tiene su propio conjunto de permisos:
Tables: select, insert, update, delete, alter, debug, flashback, on commit refresh, query rewrite, references, all
Views: select, insert, update, delete, under, references, flashback, debug
Sequence: alter, select
Packeges, Procedures, Functions (Java classes, sources…): execute, debug
Materialized Views: delete, flashback, insert, select, update
Directories: read, write
Libraries:execute
User defined types: execute, debug, under
Operators: execute
Indextypes: execute
Revoke (quitar permisos)
Esta sentencia sirve para quitar permisos (o privilegios) a un usuario o a un rol.
No dejamos nada:
REVOKE ALL PRIVILEGES FROM miusuario;
Quitamos todo:
REVOKE ALL ON T_PEDIDOS FROM miusuario;
Sintaxis, quitar un rol asignado:
REVOKE role FROM {user, | role, |PUBLIC}
Quitar un permiso de sistema:
REVOKE system_priv(s) FROM {user, | role, |PUBLIC}
REVOKE ALL FROM {user, | role, |PUBLIC}
Quitar un permiso de objeto:
REVOKE object_priv [(column1, column2..)] ON [schema.]object
FROM {user, | role, |PUBLIC} [CASCADE CONSTRAINTS] [FORCE]
REVOKE object_priv [(column1, column2..)] ON [schema.]object
FROM {user, | role, |PUBLIC} [CASCADE CONSTRAINTS] [FORCE]
REVOKE object_priv [(column1, column2..)] ON DIRECTORY directory_name
FROM {user, | role, |PUBLIC} [CASCADE CONSTRAINTS] [FORCE]
REVOKE object_priv [(column1, column2..)] ON JAVA [RE]SOURCE [schema.]object
FROM {user, | role, |PUBLIC} [CASCADE CONSTRAINTS] [FORCE]
La opción FORCE, quita todos los privilegios y descompila todos sus objetos.
Commit
Guarda los cambios de la transacción en curso.
Libera los recursos bloqueados por cualquier actualización hecha con la transacción actual (LOCK TABLE).
COMMIT [WORK] [COMMENT 'comment_text']
COMMIT [WORK] [FORCE 'force_text' [,int] ]
Si ejecutamos:
DELETE FROM T_PEDIDOS WHERE COD_PEDIDO=15;
COMMIT;
Borrar un registro y guarda los cambios.
Rollback
Deshace los cambios de la transacción en curso.
Libera los recursos bloqueados por cualquier actualización hecha con la transacción actual (LOCK TABLE).
ROLLBACK [WORK] [TO [SAVEPOINT]‘savepoint_text_identifier’];
ROLLBACK [WORK] [FORCE 'force_text'];
Si ejecutamos:
DELETE FROM T_PEDIDOS WHERE COD_PEDIDO=15;
COMMIT;
Borrar un registro pero cancela los cambios. Queda como si no hubiesemos hecho nada.
Savepoint
Sirve para marca un punto de referencia en la transacción para hacer un ROLLBACK parcial.
SAVEPOINT identificador;
Un ejemplo de uso es:
UPDATE T_PEDIDOS
SET NOMBRE=’jorge’
WHERE CODPEDIDO=125;
SAVEPOINT solouno;
UPDATE T_PEDIDOS
SET NOMBRE = ‘jorge’;
SAVEPOINT todos;
SELECT * FROM T_PEDIDOS;
ROLLBACK TO SAVEPOINT todos;
COMMIT;
Solo guardamos la primera modificación.
Transacciones
Una transacción es un grupo de acciones que hacen transformaciones consistentes en las tablas
preservando la consistencia de la base de datos. Una base de datos está en un estado consistente si obedece todas las restricciones de integridad definidas sobre ella. Los cambios de estado ocurren debido a actualizaciones, inserciones, y eliminaciones de información. Por supuesto, se quiere asegurar que la base de datos nunca entre en un estado de inconsistencia. Sin embargo, durante la ejecución de una transacción, la base de datos puede estar temporalmente en un estado inconsistente. El punto importante aquí es asegurar que la base de datos regresa a un estado consistente al fin de la ejecución de una transacción.
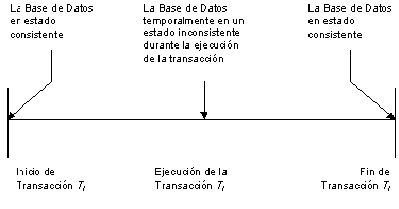
Lo que se persigue con el manejo de transacciones es por un lado tener una transparencia adecuada de las acciones concurrentes a una base de datos y por otro lado tener una transparencia adecuada en el manejo de las fallas que se pueden presentar en una base de datos.
Propiedades de una Transacción
Una transacción debe tener las propiedades ACID, que son las iniciales en inglés de las siguientes características: Atomicity, Consistency, Isolation, Durability.
Atomicidad
Una transacción constituye una unidad atómica de ejecución y se ejecuta exactamente una vez; o se realiza todo el trabajo o nada de él en absoluto.
Coherencia
Una transacción mantiene la coherencia de los datos, transformando un estado coherente de datos en otro estado coherente de datos. Los datos enlazados por una transacción deben conservarse semánticamente.
Aislamiento
Una transacción es una unidad de aislamiento y cada una se produce aislada e independientemente de las transacciones concurrentes. Una transacción nunca debe ver las fases intermedias de otra transacción.
Durabilidad
Una transacción es una unidad de recuperación. Si una transacción tiene éxito, sus actualizaciones persisten, aun cuando falle el equipo o se apague. Si una transacción no tiene éxito, el sistema permanece en el estado anterior antes de la transacción.
Operación de Transacciones
El siguiente gráfico ilustra el funcionamiento de una transacción, cuando es confirmada y cuando es cancelada.
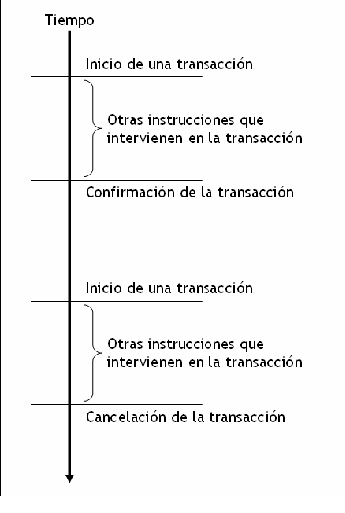
Inicio de una transacción
El inicio de una transacción es de manera automática cuando ejecutamos una sentencia insert, update, ó delete. La ejecución de cualquiera de estas sentencias da inicio a una transacción. Las instrucciones que se ejecuten a continuación formaran parte de la misma transacción.
Confirmación de una transacción
Para confirmar los cambios realizados durante una transacción utilizamos la sentencia commit.
Cancelar una transacción
Para cancelar los cambios realizados durante una transacción utilizamos la sentencia rollback.
Incrementar el salario al empleado Ricardo Marcelo (employee_id = 251) en 15%.
SQL> select employee_id, salary
2 from employees
3 where employee_id = 251;
EMPLOYEE_ID SALARY
———– ———-
251 12100
SQL> update employees
2 set salary = salary * 1.15
3 where employee_id = 251;
1 row updated.
SQL> select employee_id, salary
2 from employees
3 where employee_id = 251;
EMPLOYEE_ID SALARY
———– ———-
251 13915
SQL> commit;
Commit complete.
Set transaction
SET
TRANSACTION inicia una transaccion como “read-only (solo lectura)” o “read-write” (escritura / lectura), establece el “isolation level”, y opcionalmente asigna un segment de rollback para la. Las transacciones de “Solo Lectura (Read-only) son usadas, normalmente, para ejecutar multiples consultas sobre una o mas tablas, mientras otros usuarios modifican los datos de las tablas.
La sintaxis del comando es:
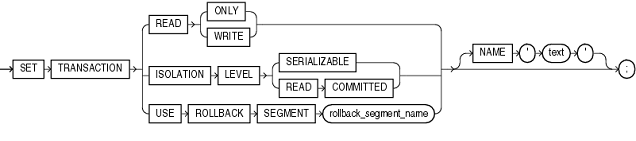
READ ONLY
Establece la transaccion como “solo lectura” de forma que las subsiguientes consultas verán solo los datos confirmados antes de las instruccion “Set transaction”.
READ WRITE
Establece la transacción como “Lectura-Escritura”, el uso de READ-WRITE, no afecta a otros usuarios. Si la transacción ejecuta manipulación de datos, Oracle asigna un segmento de rollback para la transacción.
ISOLATION LEVEL
Especifica el comportamiento de bloqueo de la transacción para la conexión
SERIALIZABLE: If a serializable transaction tries to execute a SQL data manipulation statement that modifies any table already modified by an uncommitted transaction, the statement fails.
To enable SERIALIZABLE mode, your DBA must set the Oracle initialization parameter COMPATIBLE to 7.3.0 or higher.
READ
COMMITTED: Si la transaccion de manipulacion de datos require un bloqueo de filas que estan actualmente bloqueadas por otro usuario, la transacción espera hasta que las filas sean liberadas.
USE ROLLBACK SEGMENT
Asigna a la transaccion un segment de rollback y establece la transacción como “Read-Write”, no se puede usar esta opción con “Read – Only”
NAME
Establece el nombre o comentario para la transacción.
Notas:
SET
TRANSACTION debe ser la primara sentencia e la transacción y puede aparecer solamente una vez en la transacción.
Ejemplo:
DECLARE
daily_order_total NUMBER(12,2);
weekly_order_total NUMBER(12,2);
monthly_order_total NUMBER(12,2);
BEGIN
COMMIT; — finalize la transacción anterior
SET TRANSACTION READ ONLY NAME ‘Calculando total de transacciones’;
SELECT SUM (order_total) INTO daily_order_total FROM orders
WHERE order_date = SYSDATE;
SELECT SUM (order_total) INTO weekly_order_total FROM orders
WHERE order_date = SYSDATE – 7;
SELECT SUM (order_total) INTO monthly_order_total FROM orders
WHERE order_date = SYSDATE – 30;
COMMIT; — finalize la transaccion “read-only” transaction
END;
/
Restricciones de SET TRANSACTION
Solo las sentencias SELECT
INTO, OPEN, FETCH, CLOSE, LOCK
TABLE, COMMIT, ROLLBACK pueden utilizarse en transacciones “Read-Only”.
Funciones integradas de PL/SQL
PL/SQL tiene un gran número de funciones incorporadas, sumamente útiles. A continuación vamos a ver algunas de las más utilizadas.
SYSDATE
Devuelve la fecha del sistema:
|
|
NVL
Devuelve el valor recibido como parámetro en el caso de que expresión sea NULL,o expresión en caso contrario.
|
NVL(<expresion>, <valor>) |
El siguiente ejemplo devuelve 0 si el precio es nulo, y el precio cuando está informado:
|
|
DECODE
Decode proporciona la funcionalidad de una sentencia de control de flujo if-elseif-else.
|
|
Esta función evalúa una expresión “<expr>”, si se cumple la primera condición “<cond1>” devuelve el valor1 “<val1>”, en caso contrario evalúa la siguiente condición y así hasta que una de las condiciones se cumpla. Si no se cumple ninguna condición se devuelve el valor por defecto.
Es muy común escribir la función DECODE identada como si se tratase de un bloque IF.
|
‘MEX’, ‘MEXICO’, /* Si co_pais = ‘MEX’ ==> ‘MEXICO’ */ ‘PAIS ‘||co_pais)/* ELSE ==> concatena */ |
TO_DATE
Convierte una expresión al tipo fecha. El parámetro opcional formato indica el formato de entrada de la expresión no el de salida.
|
|
En este ejemplo convertimos la expresion ’01/12/2006′ de tipo CHAR a una fecha (tipo DATE). Con el parámetro formato le indicamos que la fecha está escrita como día-mes-año para que devuelve el uno de diciembre y no el doce de enero.
|
‘DD/MM/YYYY’) |
Este otro ejemplo muestra la conversión con formato de día y hora.
|
‘DD/MM/YYYY HH24:MI:SS’) |
TO_CHAR
Convierte una expresión al tipo CHAR. El parámetro opcional formato indica el formato de salida de la expresión.
|
|
|
FROM DUAL; |
TO_NUMBER
Convierte una expresion alfanumérica en numerica. Opcionalmente podemos especificar el formato de salida.
|
|
|
|
TRUNC
Trunca una fecha o número.
Si el parámetro recibido es una fecha elimina las horas, minutos y segundos de la misma.
|
|
Si el parámetro es un número devuelve la parte entera.
|
|
LENGTH
Devuelve la longitud de un tipo CHAR.
|
|
INSTR
Busca una cadena de caracteres dentro de otra. Devuelve la posicion de la ocurrencia de la cadena buscada.
Su sintaxis es la siguiente:
|
|
|
|
REPLACE
Reemplaza un texto por otro en un expresion de busqueda.
|
|
El siguiente ejemplo reemplaza la palabra ‘HOLA’ por ‘VAYA’ en la cadena ‘HOLA MUNDO’.
|
SELECT REPLACE (‘HOLA MUNDO’,‘HOLA’, ‘VAYA’)– devuelve VAYA MUNDO |
SUBSTR
Obtiene una parte de una expresion, desde una posición de inicio hasta una determinada longitud.
|
|
|
|
UPPER
Convierte una expresion alfanumerica a mayúsculas.
|
|
LOWER
Convierte una expresion alfanumerica a minúsculas.
|
|
ROWIDTOCHAR
Convierte un ROWID a tipo caracter.
|
SELECT ROWIDTOCHAR(ROWID) |
RPAD
Añade N veces una determinada cadena de caracteres a la derecha una expresión. Muy util para generar ficheros de texto de ancho fijo.
|
|
El siguiente ejemplo añade puntos a la expresion ‘Hola mundo’ hasta alcanzar una longitud de 50 caracteres.
|
|
LPAD
Añade N veces una determinada cadena de caracteres a la izquierda de una expresión. Muy util para generar ficheros de texto de ancho fijo.
|
|
El siguiente ejemplo añade puntos a la expresion ‘Hola mundo’ hasta alcanzar una longitud de 50 caracteres.
|
|
RTRIM
Elimina los espacios en blanco a la derecha de una expresion
|
|
LTRIM
Elimina los espacios en blanco a la izquierda de una expresion
|
|
TRIM
Elimina los espacios en blanco a la izquierda y derecha de una expresion
|
|
MOD
Devuelve el resto de la división entera entre dos números.
|
|
|
SELECT MOD(20,15) – Devuelve el modulo de dividir 20/15 FROM DUAL |