Tablas del diccionario de datos:
SQL muy útiles para el administrador de Oracle (estado de la base de datos Oracle, parámetros generales, ficheros de control, conexiones actuales a Oracle, nombre del ejecutable que se utiliza, nombre del usuario, diccionario de datos (vistas y tablas)…
Vista que muestra el estado de la base de datos:
select * from v$instance
Consulta que muestra si la base de datos está abierta
select status from v$instance
Vista que muestra los parámetros generales de Oracle
select * from v$system_parameter
Versión de Oracle
select value from v$system_parameter where name = ‘compatible’
Ubicación y nombre del fichero spfile
select value from v$system_parameter where name = ‘spfile’
Ubicación y número de ficheros de control
select value from v$system_parameter where name = ‘control_files’
Nombre de la base de datos
select value from v$system_parameter where name = ‘db_name’
Vista que muestra las conexiones actuales a Oracle Para visualizarla es necesario entrar con privilegios de administrador
select osuser, username, machine, program
from v$session
order by osuser
Vista que muestra el número de conexiones actuales a Oracle agrupado por aplicación que realiza la conexión
select program Aplicacion, count(program) Numero_Sesiones
from v$session
group by program
order by Numero_Sesiones desc
Vista que muestra los usuarios de Oracle conectados y el número de sesiones por usuario
select username Usuario_Oracle, count(username) Numero_Sesiones
from v$session
group by username
order by Numero_Sesiones desc
Propietarios de objetos y número de objetos por propietario
select owner, count(owner) Numero
from dba_objects
group by owner
order by Numero desc
Diccionario de datos (incluye todas las vistas y tablas de la Base de Datos)
select * from dictionary
select table_name from dictionary
Muestra los datos de una tabla especificada (en este caso todas las tablas que lleven la cadena “EMPLO”
select * from ALL_ALL_TABLES where upper(table_name) like ‘%EMPLO%’
Tablas propiedad del usuario actual
select * from user_tables
Todos los objetos propiedad del usuario conectado a Oracle
select * from user_catalog
Consulta SQL para el DBA de Oracle que muestra los tablespaces, el espacio utilizado, el espacio libre y los ficheros de datos de los mismos:
Select t.tablespace_name “Tablespace”, t.status “Estado”,
ROUND(MAX(d.bytes)/1024/1024,2) “MB Tamaño”,
ROUND((MAX(d.bytes)/1024/1024) -
(SUM(decode(f.bytes, NULL,0, f.bytes))/1024/1024),2) “MB Usados”,
ROUND(SUM(decode(f.bytes, NULL,0, f.bytes))/1024/1024,2) “MB Libres”,
t.pct_increase “% incremento”,
SUBSTR(d.file_name,1,80) “Fichero de datos”
FROM DBA_FREE_SPACE f, DBA_DATA_FILES d, DBA_TABLESPACES t
WHERE t.tablespace_name = d.tablespace_name AND
f.tablespace_name(+) = d.tablespace_name
AND f.file_id(+) = d.file_id GROUP BY t.tablespace_name,
d.file_name, t.pct_increase, t.status ORDER BY 1,3 DESC
Productos Oracle instalados y la versión:
select * from product_component_version
Roles y privilegios por roles:
select * from role_sys_privs
Reglas de integridad y columna a la que afectan:
select constraint_name, column_name from sys.all_cons_columns
Tablas de las que es propietario un usuario, en este caso “HR”:
SELECT table_owner, table_name from sys.all_synonyms where table_owner like ‘HR’
Otra forma más efectiva (tablas de las que es propietario un usuario):
SELECT DISTINCT TABLE_NAME
FROM ALL_ALL_TABLES
WHERE OWNER LIKE ‘HR’
Parámetros de Oracle, valor actual y su descripción:
SELECT v.name, v.value value, decode(ISSYS_MODIFIABLE, ‘DEFERRED’,
‘TRUE’, ‘FALSE’) ISSYS_MODIFIABLE, decode(v.isDefault, ‘TRUE’, ‘YES’,
‘FALSE’, ‘NO’) “DEFAULT”, DECODE(ISSES_MODIFIABLE, ‘IMMEDIATE’,
‘YES’,'FALSE’, ‘NO’, ‘DEFERRED’, ‘NO’, ‘YES’) SES_MODIFIABLE,
DECODE(ISSYS_MODIFIABLE, ‘IMMEDIATE’, ‘YES’, ‘FALSE’, ‘NO’,
‘DEFERRED’, ‘YES’,'YES’) SYS_MODIFIABLE , v.description
FROM V$PARAMETER v
WHERE name not like ‘nls%’ ORDER BY 1
Usuarios de Oracle y todos sus datos (fecha de creación, estado, id, nombre, tablespace temporal,…):
Select * FROM dba_users
Tablespaces y propietarios de los mismos:
select owner, decode(partition_name, null, segment_name,
segment_name || ‘:’ || partition_name) name,
segment_type, tablespace_name,bytes,initial_extent,
next_extent, PCT_INCREASE, extents, max_extents
from dba_segments
Where 1=1 And extents > 1 order by 9 desc, 3
Últimas consultas SQL ejecutadas en Oracle y usuario que las ejecutó:
select distinct vs.sql_text, vs.sharable_mem,
vs.persistent_mem, vs.runtime_mem, vs.sorts,
vs.executions, vs.parse_calls, vs.module,
vs.buffer_gets, vs.disk_reads, vs.version_count,
vs.users_opening, vs.loads,
to_char(to_date(vs.first_load_time,
‘YYYY-MM-DD/HH24:MI:SS’),’MM/DD HH24:MI:SS’) first_load_time,
rawtohex(vs.address) address, vs.hash_value hash_value ,
rows_processed , vs.command_type, vs.parsing_user_id ,
OPTIMIZER_MODE , au.USERNAME parseuser
from v$sqlarea vs , all_users au
where (parsing_user_id != 0) AND
(au.user_id(+)=vs.parsing_user_id)
and (executions >= 1) order by buffer_gets/executions desc
Todos los ficheros de datos y su ubicación:
select * from V$DATAFILE
Ficheros temporales:
select * from V$TEMPFILE
Tablespaces:
select * from V$TABLESPACE
Otras vistas muy interesantes:
select * from V$BACKUP
select * from V$ARCHIVE
select * from V$LOG
select * from V$LOGFILE
select * from V$LOGHIST
select * from V$ARCHIVED_LOG
select * from V$DATABASE Memoria Share_Pool libre y usada
select name,to_number(value) bytes
from v$parameter where name =’shared_pool_size’
union all
select name,bytes
from v$sgastat where pool = ‘shared pool’ and name = ‘free memory’
Cursores abiertos por usuario
select b.sid, a.username, b.value Cursores_Abiertos
from v$session a,
v$sesstat b,
v$statname c
where c.name in (‘opened cursors current’)
and b.statistic# = c.statistic#
and a.sid = b.sid
and a.username is not null
and b.value >0
order by 3
Aciertos de la caché (no debe superar el 1 por ciento)
select sum(pins) Ejecuciones, sum(reloads) Fallos_cache,
trunc(sum(reloads)/sum(pins)*100,2) Porcentaje_aciertos
from v$librarycache
where namespace in (‘TABLE/PROCEDURE’,'SQL AREA’,'BODY’,'TRIGGER’);
Sentencias SQL completas ejecutadas con un texto determinado en el SQL
SELECT c.sid, d.piece, c.serial#, c.username, d.sql_text
FROM v$session c, v$sqltext d
WHERE c.sql_hash_value = d.hash_value
and upper(d.sql_text) like ‘%WHERE CAMPO LIKE%’
ORDER BY c.sid, d.piece
Una sentencia SQL concreta (filtrado por sid)
SELECT c.sid, d.piece, c.serial#, c.username, d.sql_text
FROM v$session c, v$sqltext d
WHERE c.sql_hash_value = d.hash_value
and sid = 105
ORDER BY c.sid, d.piece
//Tamaño ocupado por la base de datos
select sum(BYTES)/1024/1024 MB from DBA_EXTENTS
//Tamaño de los ficheros de datos de la base de datos
select sum(bytes)/1024/1024 MB from dba_data_files
//Tamaño ocupado por una tabla concreta sin incluir los índices de la misma
select sum(bytes)/1024/1024 MB from user_segments
where segment_type=’TABLE’ and segment_name=’NOMBRETABLA’
//Tamaño ocupado por una tabla concreta incluyendo los índices de la misma
select sum(bytes)/1024/1024 Table_Allocation_MB from user_segments
where segment_type in (‘TABLE’,'INDEX’) and
(segment_name=’NOMBRETABLA’ or segment_name in
(select index_name from user_indexes where table_name=’NOMBRETABLA’))
//Tamaño ocupado por una columna de una tabla
select sum(vsize(‘NOMBRECOLUMNA’))/1024/1024 MB from NOMBRETABLA
//Espacio ocupado por usuario
SELECT owner, SUM(BYTES)/1024/1024 FROM DBA_EXTENTS MB
group by owner
//Espacio ocupado por los diferentes segmentos (tablas, índices, undo, rollback, cluster, …)
SELECT SEGMENT_TYPE, SUM(BYTES)/1024/1024 FROM DBA_EXTENTS MB
group by SEGMENT_TYPE
//Espacio ocupado por todos los objetos de la base de datos, muestra los objetos que más ocupan primero
SELECT SEGMENT_NAME, SUM(BYTES)/1024/1024 FROM DBA_EXTENTS MB
group by SEGMENT_NAME
order by 2 desc
//Obtener todas las funciones de Oracle: NVL, ABS, LTRIM, …
SELECT distinct object_name
FROM all_arguments
WHERE package_name = ‘STANDARD’
order by object_name
//Obtener los roles existentes en Oracle Database:
select * from DBA_ROLES
//Obtener los privilegios otorgados a un rol de Oracle:
select privilege
from dba_sys_privs
where grantee = ‘NOMBRE_ROL’
Estructura de ficheros de Oracle
-
Control files (Ficheros de Control):
Los ficheros de control tiene un tamaño de entre 1 y 5 Megas. Son utilizados para mantener la consistencia interna y guiar las operaciones de recuperación. Son imprescindibles para que la BD se pueda arrancar. Contienen:
- Infomación de arranque y parada de la BD.
- Nombres de los archivos de la BD y redo log.
- Información sobre los checkpoints.
- Fecha de creación y nombre de la BD.
- Estado online y offline de los archivos.
Debe haber múltiples copias en distintos discos, mínimo dos, para progerlos de los fallos de disco. La lista de los ficheros de control se encuentra en el parámetro CONTROL_FILES, que debe modificarse con la BD parada.
- Infomación de arranque y parada de la BD.
-
Data files(fichero de datos):
En estos ficheros reside la información de la BD. Solo son modificados por el DBWR. A ellos se vuelcan los bloques sucios de la SGA cuando se hace una validación o cuando sucede un checkpoint. Las validaciones de las transacciones no producen un volcado inmediato, sino lo que se conoce por un commit diferido. Toda actualización se guarda en los ficheros de redo log, y se lleva a la BD física cuando tenemos una buena cantidad de bloques que justifiquen una operación de E/S. Almacenan los segmentos (datos, índices, rollback) de la BD. Están divididos en bloques (Bloque Oracle = c * Bloque SO), cada uno de los cuales se corresponde con un buffer del buffer cache de la SGA. En el bloque de cabecera no se guardan datos de usuario, sino la marca de tiempo del último checkpoint realizado sobre el fichero.
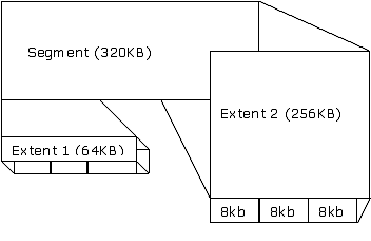
Relación entre segmentos, extensions y blques de datos:
- Tablespaces ( Espacios de tablas) : Es la unidad de almacenamiento superior, puede estar compuesta de uno o mas Data Files
- Segments (Segmentos): Un “Data file”, esta compuesto por varios segmentos.
- Extents (Extensiones): Un segmento esta compuesto por varias extensiones.
- Data blocks (Bloque de datos): Es la unidad mas pequeña de almacenamiento, su tamaño se define durante la creación de la base de datos y no se puede modificar.
La siguiente figura muestra la relación entre segmentos, extensions y blques de datos:
Redo Log files:
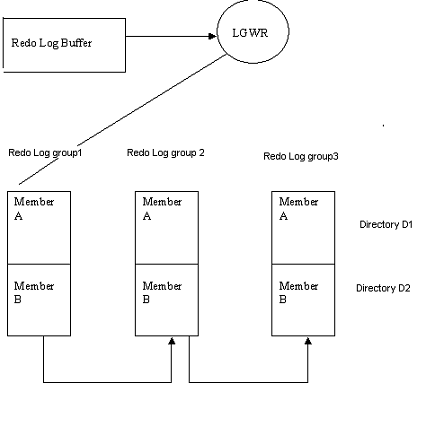
En ellos se graba toda operación que se efectue en la BD y sirven de salvaguarda de la misma. Tiene que haber por lo menos 2, uno de ellos debe estar activo, online, y se escribe en ellos de forma cíclica. Existe la posibilidad de almacenar los distintos ficheros de redo log en el tiempo mediante el modo ARCHIVER. Así, se puede guardar toda la evolución de la BD desde un punto dado del tiempo.
Una opción es la utilización de archivos redo log multiplexados:
Permite al LGWR escribir simultaneamente la misma información en múltiples archivos redo log.
Se utiliza para protegerse contra fallos en el disco.
Da una alta disponibilidad a los archivos redo log activos u online.
Esto se hace definiendo el número de grupos y de miembros de archivos redo log que van a funcionar en paralelo:
grupos: funcionan como ficheros redo log normales, uno de ellos está activo y el resto espera su turno.
Su nombre lleva incorporado una numeración.
Deben contener todos el mismo número de miembros.
miembros: cada escritura de un registro redo log se lleva a cabo en todos los miembros del grupo activo en ese momento. Los miembros deben:
tener el mismo tamaño y el mismo número de secuencia.
deben tener nombres similares y estar en diferentes discos para proteger contra fallos de una manera efectiva.
Cuando se produce algún fallo en los ficheros de redo log o en el proceso LGWR:
Si la escritura en un fichero redo log falla pero el LGWR puede escribir al menos en uno de los miembros del grupo, lo hace , ignorando el fichero inaccesible y registrando un fallo en un fichero de traza o alerta.
Si el siguiente grupo no ha sido archivado (modo ARCHIVELOG) antes del cambio de grupo que lo pone activo, ORACLE espera hasta que se produzca el archivado.
Si fallan todos los miembros de un grupo mientras el LGWR trata de escribir, la instancia se para y necesita recupeción al arrancar.
Ficheros de Traza
Orace crea ficheros de texto llamados de traza para ayudar en la diagnosis de problemas y en el ajuste del SGBD. Cada proceso del servidor escribe en un fichero de traza asociado cuando es necesario. Los procesos de usuarios también pueden tener asociados ficheros de traza. La situación de estos ficheros de traza del sistema se especifica por el parámetro BACKGROUND_DUMP_DEST, y los de usuario por USER_DUMP_DEST. Oracle crea ficheros de traza automáticamente cuando ocurre algún error.
Un parámetro muy frecuentemente utilizado por los desarrolladores Oracle es el SQL_TRACE, que cuando está puesto a TRUE produce que toda sentencia SQL ejecutada genere información en los ficheros de traza. Este parámetro se puede variar con el siguiente comando:
alert_<>.log:
- Tablespaces ( Espacios de tablas) : Es la unidad de almacenamiento superior, puede estar compuesta de uno o mas Data Files
-
Spfile.ora init.ora :
El spfile es un fichero binario que contiene la especificación de los parámetros de inicialización dela base de datos . el erchivo spfile.ora Este es el primer archivo que va a “buscar” oracle en su arranque de base de datos. Si no encuentra este archivo entonces irá a buscar el archivo init.ora ( fichero de texto )
A partir de la versión 9, Oracle introdujo el fichero de parámetros de arranque (más conocido como ‘spfile’) como mejora a los antiguos aranques con los ‘init.ora’.
Las ventajas que tienen estos nuevos ficheros sobre los antiguos son, entre otras:
·Los ‘spfile’ son binarios, mientras que los ‘init.ora’ eran ficheros de texto.
·Con los ‘spfile’ se puede arrancar una instancia en modo remoto, mientras que con los ‘init.ora’ el fichero debe estar accesible (residir en el mismo sistema de ficheros) desde el que se realiza el aranque.
·Los ‘ALTER SYSTEM’ son guardados (si se quiere) automáticamente en los ‘spfile’, mientras que en los ‘init.ora’ no.
·Los ‘spfile’ pueden ser incluidos en los ‘backups’ de RMAN, mientras que los ‘init.ora’ no.
No obstante, y debido a que los ‘init.ora’ pueden ser aun de gran utilidad (arrancar una instancia cuando hay problemas, sobre todo), Oracle los ha ha mantenido (aunque recomienda encarecidamente el uso de los ‘spfile’).
La siguiente figura muestra el uso de los ficheros “Redo Log” :
Localización de ficheros clave:
select ‘control’ tipo, substr(name,1,70) nombre FROM v$controlfile
union all
select ‘datos’ tipo, substr(name,1,70) nombre from v$datafile
union all
select ‘redolog’ tipo, substr(member,1,70) nombre from v$logfile
La instancia oracle
Una instancia de Oracle está conformada por varios procesos y espacios de memoria compartida que son necesarios para acceder a la información contenida en la base de datos.
La instancia está conformada por procesos del usuario, procesos que se ejecutan en el background de Oracle y los espacios de memoria que comparten estos procesos.
Estructura de la memoria de oracle
El Área Global del Sistema (SGA)
El SGA es un área de memoria compartida que se utiliza para almacenar información de control y de datos de la instancia. Se crea cuando la instancia es levantada y se borra cuando ésta se deja de usar (cuando se hace shutdown). La información que se almacena en esta área consiste de los siguientes elementos, cada uno de ellos con un tamaño fijo:
- El buffer de caché (database buffer cache) Almacena los bloques de datos utilizados recientemente (se hayan o no confirmado sus cambios en el disco). Al utilizarse este buffer se reducen las operaciones de entrada y salida y por esto se mejora el rendimiento.
- El buffer de redo log: Guarda los cambios efectuados en la base de datos. Estos buffers escriben en el archivo físico de redo log tan rápido como se pueda sin perder eficiencia. Este último archivo se utiliza para recuperar la base de datos ante eventuales fallas del sistema.
- El área shared pool: Esta sola área almacena estructuras de memoria compartida, tales como las áreas de código SQL compartido e información interna del diccionario. Una cantidad insuficiente de espacio asignado a esta área podría redundar en problemas de rendimiento.
En esta zona se encuentran las sentencias SQL que han sido analizadas. El analisis sintáctico de las sentencias SQL lleva su tiempo y Oracle mantiene las estructuras asociadas a cada sentencia SQL analizada durante el tiempo que pueda para ver si puede reutilizarlas. Antes de analizar una sentencia SQL, Oracle mira a ver si encuentra otra sentencia exactamente igual en la zona de SQL compartido. Si es así, no la analiza y pasa directamente a ejecutar la que mantinene en memoria. De esta manera se premia la uniformidad en la programación de las aplicaciones. La igualdad se entiende que es lexicografica, espacios en blanco y variables incluidas. El contenido de la zona de SQL compartido es:
- Plan de ejecución de la sentencia SQL.
- Texto de la sentencia.
- Lista de objetos referenciados.
Los pasos de procesamiento de cada petición de análisis de una sentencia SQL son:
- Comprobar si la sentencia se encuentra en el área compartida.
- Comprobar si los objetos referenciados son los mismos.
- Comprobar si el usuario tiene acceso a los objetos referenciados.
Si no, la sentencia es nueva, se analiza y los datos de análisis se almacenan en la zona de SQL compartida.
También se almacena en la zona de SQL compartido el caché del diccionario. La información sobre los objetos de la BD se encuentra almacenada en las tablas del diccionario. Cuando esta información se necesita, se leen las tablas del diccionario y su información se guarda en el caché del diccionario de la SGA.
- El caché de biblioteca se utiliza para almacenar código SQL compartido. Aquí se manejan los árboles de parsing y el plan de ejecución de las queries. Si varias aplicaciones utilizan la misma sentencia SQL, esta área compartida garantiza el acceso por parte de cualquiera de ellas en cualquier instante.
- El caché del diccionario de datos está conformado por un grupo de tablas y vistas que se identifican la base de datos. La información que se almacena aquí guarda relación con la estructura lógica y física de la base de datos. El diccionario de datos contiene información tal como los privilegios de los usuarios, restricciones de integridad definidas para algunas tablas, nombres y tipos de datos de todas las columnas y otra información acerca del espacio asignado y utilizado por los objetos de un esquema.
El Área Global de Programas (PGA)
Esta área de memoria contiene datos e información de control para los procesos que se ejecutan en el servidor de Oracle (relacionados con la base de datos, por supuesto). El tamaño y contenido de la PGA depende de las opciones del servidor que se hayan instalado.
Procesos de Una Instancia de Oracle
Existen dos tipos categorias de procesos
- Procesos de usuario
-
Procesos de sistema
La siguiente figura muestra la relación entre los procesos de usuario, porcesos de servidor, PGA y session:
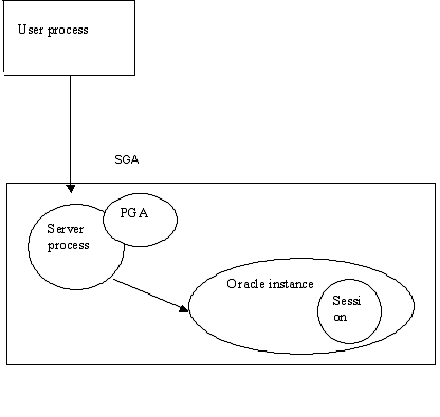
La primera interaccion con Oracle, comienza desde el PC del usuario que crea el procesos de usuario, esté comunica con el procesos de servidor, la PGA es usada para almacenar información asociada con la sesión.
Oracle background processes (Procesos en segundo Plano)
Oracle cuenta con un gran número de procesis en Segundo plano, estos estan categorizados en:
- Requeridos
- Opcionales
Algunos procesos en Segundo Plano son:
DBWR
El proceso DBWR es el responsable de gestionar el contenido de los buffers de datos y del caché del diccionario. Él lee los bloques de los ficheros de datos y los almacena en la SGA. Luego escribe en los ficheros de datos los bloques cuyo contenido ha variado. La escritura de los bloques a disco es diferida buscando mejorar la eficiencia de la E/S.
Es el único proceso que puede escribir en la BD. Esto asegura la integridad. Se encarga de escribir los bloques de datos modificados por las transacciones, tomando la información del buffer de la BD cuando se valida una transacción. Cada validación no se lleva a la BD física de manera inmediata sino que los bloques de la BD modificados se vuelcan a los ficheros de datos periodicamente o cuando sucede algún checkpoint o punto de sincronizaión: grabación diferida:
- Los bloques del buffer de la BD (bloques del segmento de rollback y bloques de datos) menos recientemente utilizados son volcados en el disco continuamente para dejar sitio a los nuevos bloques.
- El bloque del segmento de rollback se escribe SIEMPRE antes que el correspondiente bloque de datos.
- Múltiples transacciones pueden solapar los cambios en un sólo bloque antes de escribirlo en el disco.
Mientras, para que se mantenga la integridad y coherencia de la BD, todas las operaciones se guardan en los ficheros de redo log. El proceso de escritura es asíncrono y puede realizar grabaciones multibloque para aumentar la velocidad.
LGWR
El proceso LGWR es el encargado de escribir los registros redo log en los ficheros redo log. Los registros redo log siempre contienen el estado más reciente de la BD, ya que puede que el DBWR deba esperar para escribir los bloques modificados desde el buffer de datos a los ficheros de datos.
Conviene tener en cuenta que el LGWR es el único proceso que escribe en los ficheros de redo log y el único que lee directamente los buffers de redo log durante el funcionamiento normal de la BD.
Coloca la información de los redo log buffers en los ficheros de redo log. Los redo log buffers almacenan una copia de las transacciones que se llevan a cabo en la BD. Esto se produce:
- a cada validación de transacción, y antes de que se comunique al proceso que todo ha ido bien,
- cuando se llena el grupo de buffers de redo log
- cuando el DBWR escribe buffers de datos modificados en disco.
Así, aunque los ficheros de DB no se actualicen en ese instante con los buffers de BD, la operación queda guardada y se puede reproducir. Oracle no tiene que consumir sus recursos escribiendo el resultado de las modificaciones de los datos en los archivos de datos de manera inmediata. Esto se hace porque los registros de redo log casi siempre tendrán un tamaño menor que los bloques afectados por las modificaciones de una transacción, y por lo tanto el tiempo que emplea en guardarlos es menor que el que emplearía en almacenar los bloques sucios resultado de una transacción; que ya serán trasladados a los ficheros por el DBWR. El LGWR es un proceso único, para asegurar la integridad. Es asíncrono. Además permite las grabaciones multibloque.
CKPT
Este proceso escribe en los ficheros de control los checkpoints. Estos puntos de sincronización son referencias al estado coherente de todos los ficheros de la BD en un instante determinado, en un punto de sincronización. Esto significa que los bloques sucios de la BD se vuelcan a los ficheros de BD, asegurándose de que todos los bloques de datos modificados desde el último checkpoint se escriben realmente en los ficheros de datos y no sólo en los ficheros redo log; y que los ficheros de redo log también almacenan los registros de redo log hasta este instante. La secuencia de puntos de control se almacena en los ficheros de datos, redo log y control. Los checkpoints se producen cuando:
- un espacio de tabla se pone inactivo, offline,
- se llena el fichero de redo log activo,
- se para la BD,
- el número de bloques escritos en el redo log desde el último checkpoint alcanza el límite definido en el parámetro LOG_CHECKPOINT_INTERVAL,
- cuando transcurra el número de segundos indicado por el parámetro LOG_CHECKPOINT_TIMEOUT desde el último checkpoint.
PMON
Este proceso restaura las transacciones no validadas de los procesos de usuario que abortan, liberando los bloqueos y los recursos de la SGA. Asume la identidad del usuario que ha fallado, liberando todos los recursos de la BD que estuviera utilizando, y anula la transacción cancelada. Este proceso se despierta regularmente para comprobar si su intervención es necesaria..
SMON
El SMON es el supervisor del sistema y se encarga de todas las recuperaciones que sean necesarias durante el arranque. Esto puede ser necesario si la BD se paró inesperadamente por fallo físico, lógico u otras causas. Este proceso realiza la recuperación de la instancia de BD a partir de los ficheros redo log. Además ímpia los segmentos temporales no utilizados y compacta los huecos libres contiguos en los ficheros de datos. Este proceso se despierta regularmente para comprobar si debe intervenir.
ARCH:
El proceso archivador tiene que ver con los ficheros redo log. Por defecto, estos ficheros se reutilizan de manera cíclica de modo que se van perdiendo los registros redo log que tienen una cierta antiguedad. Cuando la BD se ejecuta en modo ARCHIVELOG, antes de reutilizar un fichero redo log realiza una copia del mismo. De esta manera se mantiene una copia de todos los registros redo log por si fueran necesarios para una recuperación. Este es el trabajo del proceso archivador.
La siguiente figura muestra la estructura de Oracle en detalle:
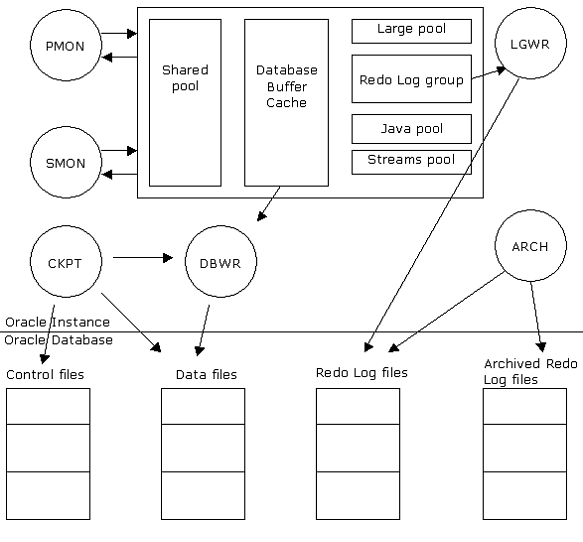
La figura anterior muestra los diferentes components del SGA, Procesos en segudo plano y sus interacciones con los ficheros de control, los ficheros Redo Log, y los
Listener
TNS Listener es un proceso servidor que provee la conectividad de red con la base de datos Oracle. El listener está configurado para escuchar la conexión en un puerto específico en el servidor de base de datos. Cuando una se pide una conexión a la base de datos, el listener devuelve la información relativa a la conexión. La información de una conexión para una instancia de una base de datos provee el nombre de usuario, la contraseña y el SID de la base de datos. Si estos datos no son correctos se devolverá un mensaje de error.
- Por defecto el puerto del listener es el 1521
- El listener no limita el número de conexiones a la base de datos
Toda la información del listener la contiene un archivo denominado listener.ora ( $ORACLE_HOME/network/admin. )
El comando para gestionar el listener es lsnrctl. Mediante este comando podemos:
- Parar el listener.
- Ver el estado del listener.
- Arrancar el listener.
- Rearrancar el listener.
Seguridad listener oracle 10g (securing the listener)
El principal paso para realizar la seguridad en el listener es ponerle una contraseña password.
El primer método para poner una contraseña al listener es editando el fichero listener.ora y escribiendo la siguiente línea:
PASSWORDS_LISTENER = orapass
Cuando guardemos el fichero con los cambios realizamos un reload del listener
lsnrctl> reload
Nota: El comando para entrar en el listener es lsnrctl ( $ORACLE_HOME/bin )
El segundo método para poder cambiar la contraseña al listener es el siguiente:
lsnrctl> change_password
Este comando te pedirá la clave antigua y la nueva clave.
Si es la primera vez que ejecutas este comando la contraseña antigua ( old password ) habrá que dejarla en blanco.
El comando SET y SAVE CONFIG permite guardar esos cambios en el listener porque ahora el listener está gobernado por un password.
lsnrctl > set password
lsnrctl > save config
La información antigua se guardará enlistener.bck y listener.ora se actualizará con los nuevos datos.
Ejemplo de configuración del listener.ora
LISTENER9 =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 193.168.4.220)(PORT = 2484))
)
)
)
SID_LIST_LISTENER9 =
(SID_LIST =
(SID_DESC =
(GLOBAL_DBNAME = orasite)
(ORACLE_HOME = /oracle9/product/9.2.0)
(SID_NAME = orasite)
)
)
Parámetros del archivo:
HOST: Dirección ip del servidor de base de datos
PORT: Puerto de escucha de la base de datos ( por defecto suele ser el 1521 )
CLOBAL_DB_NAME: Nombre de la base de datos
ORACLE_HOME: Directorio de instalación de ORACLE ( ORACLE_HOME )
SID_NAME: SID de la base de datos (muchas veces coincide con el GLOBAL_DB_NAME )
Este archivo incluye:
- Direcciones de protocolo en las que acepta solicitudes de conexión.
- Servicios de base de datos
- Parámetros de control utilizados por el listener.
Actualización de los parámetros del sistema
Introducción
Oracle es una base de datos configurable mediante una serie de parámetros, el administrador puede optimizar los valores de esta base de datos. Estos parámetros de optimización y configuración de base de datos se almacenan en un fichero. Este fichero es el primero al que se accede al arrancar la base de datos oracle. El fichero de parámetros del que estamos hablando se denomina init.ora. En este fichero como hemos indicado anteriormente escribiremos los parámetros de configuración de oracle, pero si en este archivo alguno de los parámetros de oracle configurables no se encuentra este parámetro tomará el valor que oracle tenga por defecto.
Mostrar la lista de todos los parámetros
SELECT p.name,
p.type,
p.value,
p.isses_modifiable,
p.issys_modifiable,
p.isinstance_modifiable
FROM v$parameter p
ORDER BY p.name;
Tipos de parametros existentes
Existen tres tipos de parámetros en oracle:
- Parámetros “fijos”: Son parámetros que una vez instalada la base de datos no se pueden volver a modificar / configurar. El juego de caracteres es un claro ejemplo.
- Parámetros Estáticos: Son parámetros que se pueden modificar, pero su modificación implica cerrar la base de datos y volverla a abrir para que los lea del fichero y pueda realizar el cambio.
- Parámetros Dinámicos: Son parámetros cuyo valor se puede cambiar sin necesidad de cerrar la base de datos a diferencia de los estáticos.
Para saber si un parámetro es fijo, estático o dinámico os remito a la documentación oficial de oracle: parametros inicializacion
Ubicación y nomenclatura del fichero init.ora
El archivo init.ora lo podemos encontrar en Windows dentro del directorio ORACLE_HOME\database y en UNIX dentro del directorio ORACLE_HOME/dbs. El nombre del archivo siempre corresponderá a initsid.ora siendo sid el nombre de la base de datos.( Este es el nombre que oracle buscará al arrancar la base de datos)
Spfile.ora
Init.ora no es el único archivo de parámetros que podemos encontrar en las base de datos oracle. A partir de la versión 9 encontramos el archivo spfile.ora. Este es el primer archivo que va a “buscar” oracle en su arranque de base de datos. Si no encuentra este archivo entonces irá a buscar el archivo init.ora Este archivo está codificado y las modificaciones en él se realizarán mediante una serie de comandos oracle que posteriormente indicaremos. Es cierto que este archivo podemos intentar abrirlo con el notepad solo que probablemente quede corrupto o inservible. La ubicación de este archivo es la misma que la del init.ora
Cambio de los valores de los parámetros
Si queremos realizar algún cambio en algún parámetro de base de datos tenemos que diferenciar dos cosas:
- Si el cambio es en el init.ora o spfile.ora
- Tipo de parámetro sobre el que se quiere hacer el cambio
Cambios en el init.ora
Vamos a explicar como realizar un cambio en el fichero init.ora, para ello tenemos que tener en cuenta el tipo de parámetro que vamos a cambiar. Como hemos visto al principio de este articulo, existen tres tipos de parámetros, dejando a un lado los parámetros fijos (aquellos que no se pueden cambiar una vez instalada la base de datos) nos quedan los parámetros estáticos y los dinámicos. Para modificar un parámetro estático nos basta con editar el fichero init.ora y modificar o añadir ahí el parámetro nuevo reiniciando la base de datos para que coja estos cambios. En cuando a los parámetros dinámicos podemos cambiarlos en tiempo real sin parar la base de datos mediante la siguiente sentencia.
SQL> ALTER SYSTEM SET PARAMETRO = VALOR;
Este cambio pasa automáticamente a ser efectivo en la base de datos, aunque tenemos que tener en cuenta que la próxima vez que la base de datos sea iniciada lo que va a leer es el fichero de parámetros init.ora y si este cambio no se ha realizado en este fichero la base de datos obtendrá lo que en él ponga.
Cambios en el spfile.ora
Como hemos comentado este fichero lo podemos encontrar en las bases de datos a partir de la versión 9 y como también hemos comentado es un fichero no editable por lo que los cambios se realizan a través del comando ALTER SYSTEM añadiendo la cláusula SCOPE con una serie de valores que detallaremos a continuación con un ejemplo:
Vamos a cambiar el parámetro shared_pool_size a 150 Megas
SQL> ALTER SYSTEM set shared_pool_size= 150 SCOPE=spfile
En este caso hemos cambiado el parámetro y estos cambios se han recogido en el archivo spfile, por lo tanto tomarán su cambio cuando sea reiniciada la base de datos.
SQL> ALTER SYSTEM set shared_pool_size= 150 SCOPE=memory
En este caso se ha cambiado el parámetro y estos cambios se han recogido solamente en memoria, esto quiere decir que se hacen efectivos al momento (si el tipo de parámetro lo permite) pero este cambio no se ver reflejado en el archivo de parámetros por lo tanto cuando volvamos a reiniciar la base de datos tomará el valor que en este tenía ( el antiguo ).
SQL> ALTER SYSTEM set shared_pool_size= 150 SCOPE=both
En este caso el parámetro se cambia tanto en el spfile como en memoria
Perdida del spfile
Como hemos comentado en un par de ocasiones el archivo spfile no es un archivo editable y si se edita con notepad y se vuelve a guardar lo mas probable es que se corrompa. En caso de perdida de este archivo es bueno tener un init.ora a partir del cual podemos recuperarlo o recrearlo. Si tenemos un init.ora la sentencia para hacer esto es la siguiente:
SQL> CREATE SPFILE [='spfile_name'] FROM PFILE [='Spfile_name'];
Control de sesiones (kill session)
Existen diferentes maneras de matar una sesión de oracle tanto dentro de oracle como fuera:
El primer paso es identificar la sesión que queremos matar:
SET LINESIZE 100 COLUMN spid FORMAT A10 COLUMN username FORMAT A10 COLUMN program FORMAT A45
SELECT s.inst_id, s.sid, s.serial#, p.spid, s.username, s.program FROM gv$session s JOIN gv$process p ON p.addr = s.paddr AND p.inst_id = s.inst_id WHERE s.type != 'BACKGROUND';
INST_ID SID SERIAL# SPID USERNAME PROGRAM ---------- ---------- ---------- ---------- ---------- --------------------------------------------- 1 30 15 3859 TEST sqlplus@oel5-11gr2.localdomain (TNS V1-V3) 1 23 287 3834 SYS sqlplus@oel5-11gr2.localdomain (TNS V1-V3) 1 40 387 4663 oracle@oel5-11gr2.localdomain (J000) 1 38 125 4665 oracle@oel5-11gr2.localdomain (J001) Los valores SID y SERIAL# son los que se utilizaran en los comandos que explicamos más delante.
ALTER SYSTEM KILL SESSION
La sintaxis básica para matar una sesión es la siguiente:
SQL> ALTER SYSTEM KILL SESSION ‘sid,serial#’;
En un ambiente RAC, opcionalmente se puede añadir el identificador de la instancia INST_ID, lo obtenemos de la vista GV$SESSION view. Este permite matar una sesión desde otro de los nodos de RAC.
SQL> ALTER SYSTEM KILL SESSION ‘sid,serial#@inst_id’;
El comando KILL SESSION no mata la sesión, simplemente le indica a la sesión que debe matarse ella misma. En algunas situaciones como en la espera de una respuesta de una base de datos remota o cuando se esta haciendo un roll back a una transacción, la sesión no se mata a si misma inmediatamente, espera a que termine la operación que está realizando. En estos casos la sesión adquiere el status de “marked for kill”, y se mata lo antes posible
Además de la syntaxix descrita anteriormente, se puede añadir la clausula IMMEDIATE.
SQL> ALTER SYSTEM KILL SESSION ‘sid,serial#’ IMMEDIATE;
Esto no afecta al trabajo que hace el comando, pero devuelve el control a la sesión inmediatamente, en vez de esperar la confirmación de que se ha matado la sesión.
Si la sesión marcada persiste demasiado en el tiempo se puede intentar matar el proceso a nivel de sistema operativo, antes de hacer esto es conveniente comprobar que la sesión no está haciendo rollback. Podemos comprobar esto con el script (session_undo.sql), lo tenéis en la página de scripts. Si el valor de USED_UREC decrece para la sesión en cuestión es mejor dejar que termine el rollback antes de matar la sesión a nivel de sistema operativo.
ALTER SYSTEM DISCONNECT SESSION
Oracle 11g introduce la sintaxis ALTER SYSTEM DISCONNECT SESSION un Nuevo método de matar una sesion Oracle. Lo que hace este comando es matar el proceso de servidor dedicado ( o circuito virtual cuando se utilizan los Shared Sever), lo que es equivalente a matar el proceso desde el sistema operativo. La sintaxis básica es similar a la del comando KILL SESSION más la clausula POST_TRANSACTION
SQL> ALTER SYSTEM DISCONNECT SESSION ‘sid,serial#’ POST_TRANSACTION;
SQL> ALTER SYSTEM DISCONNECT SESSION ‘sid,serial#’ IMMEDIATE;
La clausula POST_TRANSACTION espera a que la transacción se complete antes de desconectar la sesión.
Matar una sesión en windows
C:> orakill ORACLE_SID spid
Matar una sesión en Unix
% kill spid
Si después de unos minutos no ha muerto utilizar
% kill -9 spid
Para verificar que el spid coincide con el proceso del sistema operativo:
% ps -ef | grep ora